最近把之前的《R 数据科学》的笔记整理一下,大概每篇文章整理 2-3 章,这本书有中英文两版,不知道为什么中文版比英文版少了一章,而且一些关键内容也有所删减,所以大家学习这本书的时候以英文版为准。
电子书下载地址:《R4ds》
源代码地址:https://github.com/hadley/r4ds
# 作者简介:
哈德利・威克姆(Hadley Wickham)
RStudio 首席科学家,统计学家,斯坦福大学、奥克兰大学、莱斯大学兼职统计学教授。已被下载数百万次的 ggplot2 等多款知名 R 包的开发者,一直致力于让普罗大众更容易上手数据分析,被 R 社区誉为 “改变了 R 的人”。另著有《R 包开发》等书。
加勒特・格罗勒芒德(Garrett Grolemund)
RStudio 数据科学家,知名 R 培训师,曾受邀在 Google、eBay 等诸多公司讲授 R 语言和数据科学,在 DataCamp 开授的 R 相关课程备受 R 开发者喜爱。另著有《R 语言入门与实践》。
# 第一章:使用 ggplot2 进行数据可视化
# 1.1 简介
准备工作
本章重点讨论 tidyverse 的一个核心 R 包 ——ggplot2。为了访问本章用到的数据集、帮助页面和函数,需要先运行以下代码来加载 tidyverse
install.packages("tidyverse") | |
library(tidyverse) |
# 1.2 第一步
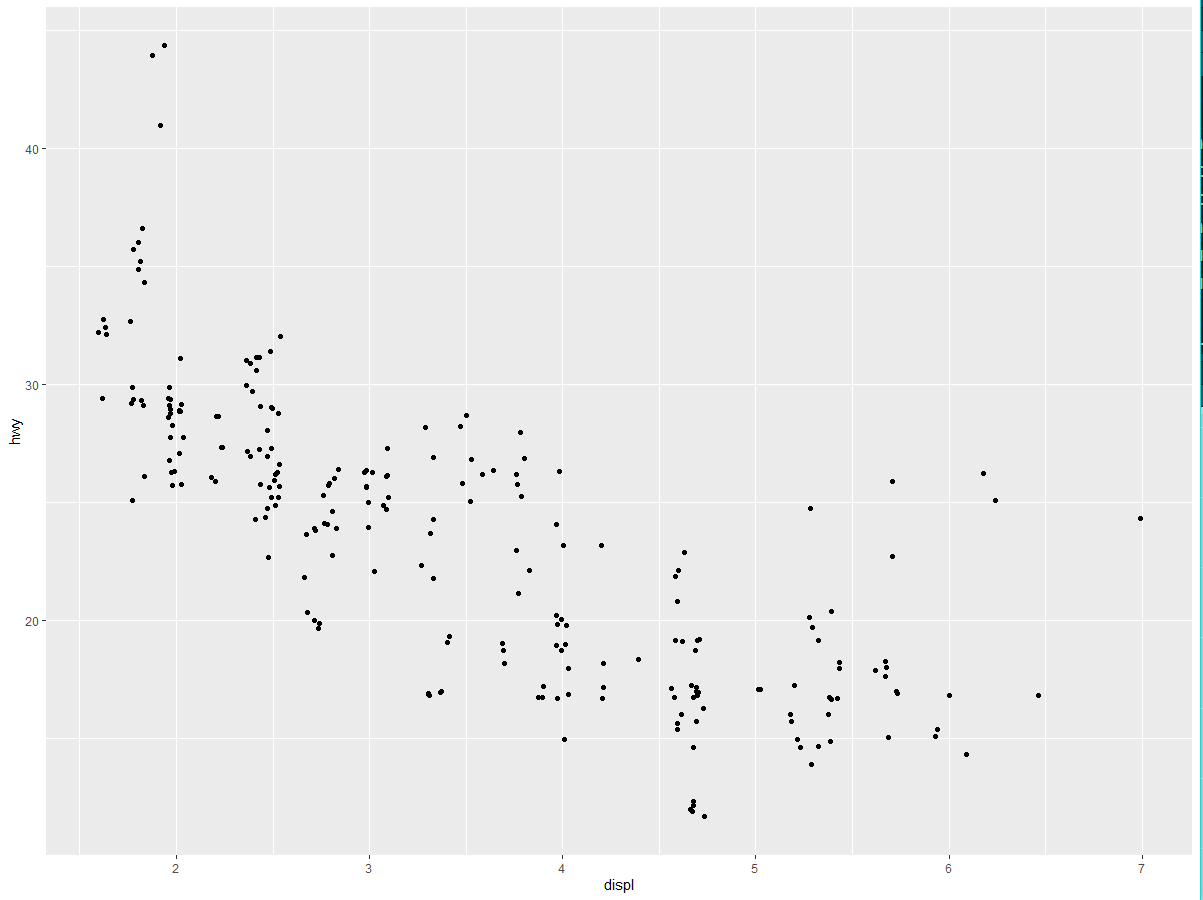
我们使用第一张图来回答问题:大引擎汽车比小引擎汽车更耗油吗?你可能已经有了答案,但应该努力让答案更精确一些。引擎大小与燃油效率之间是什么关系?是正相关,还是负相关?是线性关系,还是非线性关系?
# 1.2.1 mpg 数据框
你可以使用 ggplot2 包中的 mpg 数据框(即 ggplot2::mpg)来检验自己的答案。数据框是变量(列)和观测(行)的矩形集合。mpg 包含了由美国环境保护协会收集的 38 种车型的观测数据。
> mpg | |
# A tibble: 234 x 11 | |
manufacturer model displ year cyl trans drv cty hwy fl | |
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> | |
1 audi a4 1.8 1999 4 auto~ f 18 29 p | |
2 audi a4 1.8 1999 4 manu~ f 21 29 p | |
3 audi a4 2 2008 4 manu~ f 20 31 p | |
4 audi a4 2 2008 4 auto~ f 21 30 p | |
5 audi a4 2.8 1999 6 auto~ f 16 26 p | |
6 audi a4 2.8 1999 6 manu~ f 18 26 p | |
7 audi a4 3.1 2008 6 auto~ f 18 27 p | |
8 audi a4 q~ 1.8 1999 4 manu~ 4 18 26 p | |
9 audi a4 q~ 1.8 1999 4 auto~ 4 16 25 p | |
10 audi a4 q~ 2 2008 4 manu~ 4 20 28 p | |
# ... with 224 more rows, and 1 more variable: class <chr> |
mpg 中包括如下变量。
・displ:引擎大小,单位为升。
・hwy:汽车在高速公路上行驶时的燃油效率,单位为英里 / 加仑(mpg)。与燃油效率高的汽车相比,燃油效率低的汽车在行驶相同距离时要消耗更多燃油。要想了解更多关于 mpg 的信息,可以使用?mpg 命令打开其帮助页面。
# 1.2.2 创建 ggplot 图形
为了绘制 mpg 的图形,运行以下代码将 displ 放在 x 轴,hwy 放在 y 轴:
ggplot(data = mpg) + | |
geom_point(mapping = aes(x = displ, y = hwy)) |
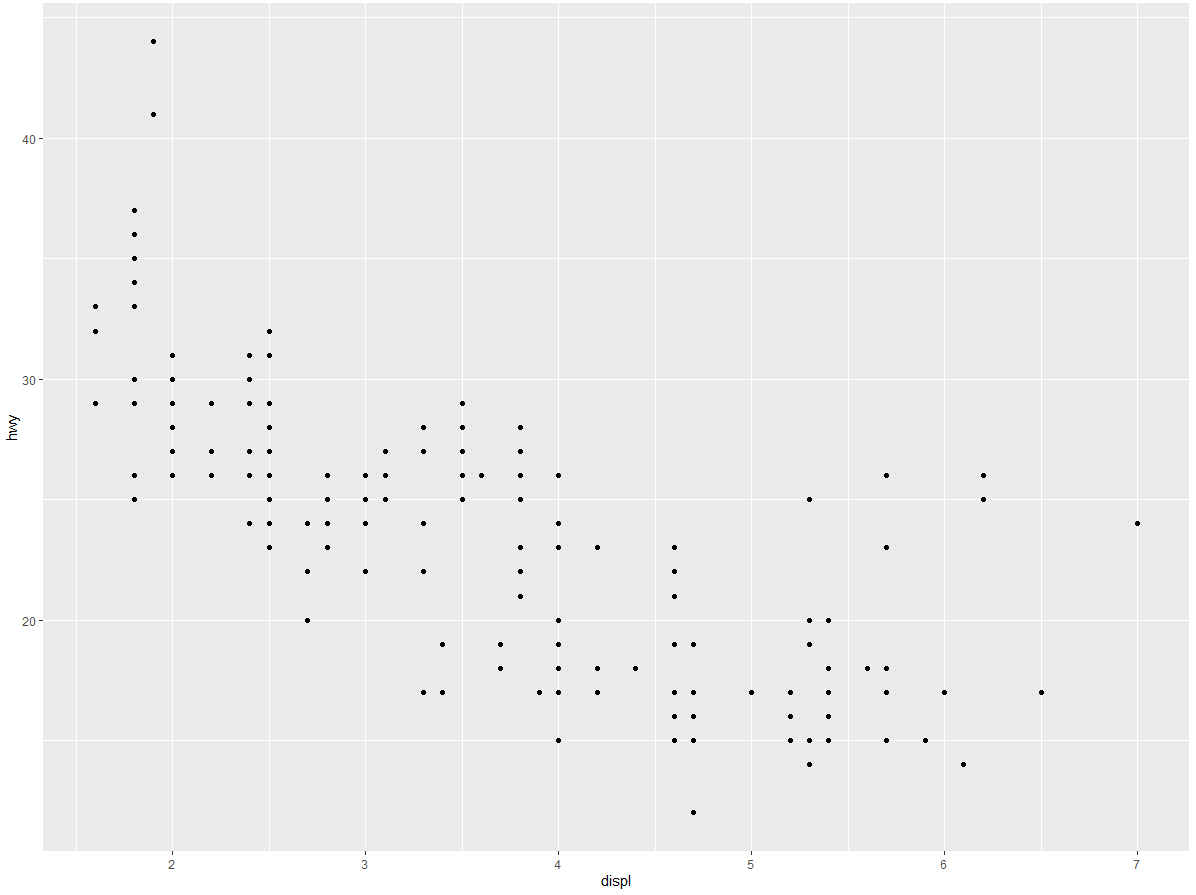
上图显示出引擎大小(displ)和燃油效率(hwy)之间是负相关关系。换句话说,大引擎汽车更耗油。
在 ggplot2 中,你可以使用 ggplot () 函数开始绘图。ggplot () 创建了一个坐标系,你可以在它上面添加图层。ggplot () 的第一个参数是要在图中使用的数据集。ggplot (data = mpg) 会创建一张空白图,因为这张图没什么意思,所以就不在这里展示了。
函数 geom_point () 向图中添加一个点层,这样就可以创建一张散点图。ggplot2 中包含了多种几何对象函数,每种函数都可以向图中添加不同类型的图层。
ggplot2 中的每个几何对象函数都有一个 mapping 参数。这个参数定义了如何将数据集中的变量映射为图形属性。mapping 参数总是与 aes () 函数成对出现,aes () 函数的 x 参数和 y 参数分别指定了映射到 x 轴的变量与映射到 y 轴的变量。ggplot2 在 data 参数中寻找映射变量,本例中就是 mpg。
# 1.2.3 绘图模板
将上面的代码转换为一个可重用的 ggplot2 绘图模板。要想生成一张图,将以下代码中的尖括号部分替换为数据集、几何对象函数或映射集合即可:
ggplot(data = <DATA>) + | |
<GEOM_FUNCTION>(mapping = aes(<MAPPINGS>)) |
# 1.2.4 练习
(1) 运行 ggplot (data = mpg),你会看到什么?
一片空白
(2) 数据集 mpg 中有多少行?多少列?
234 行 11 列
(3) 变量 drv 的意义是什么?使用?mpg 命令阅读帮助文件以找出答案。
传动系的类型,其中 f = 前轮驱动,r = 后轮驱动,4 = 4wd
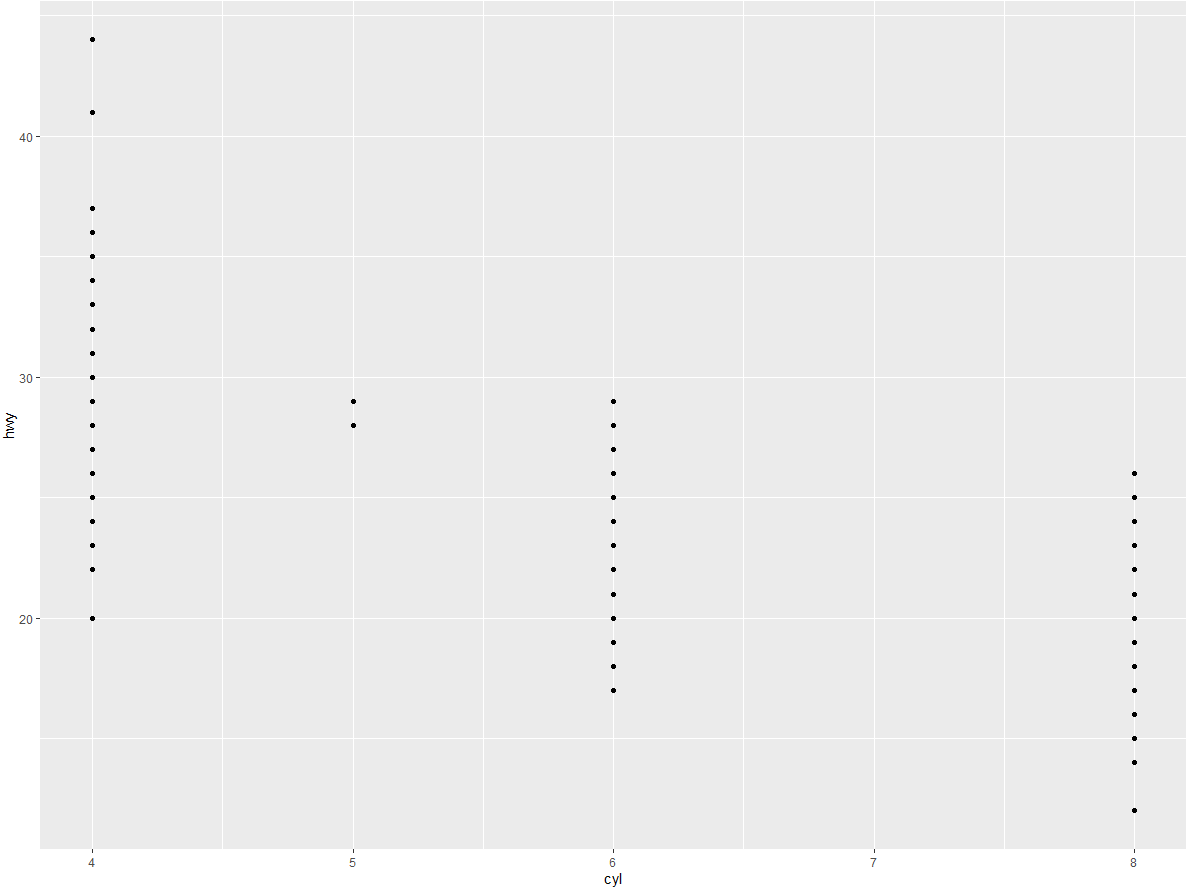
(4) 使用 hwy 和 cyl 绘制一张散点图。
ggplot(data = mpg) + | |
geom_point(mapping = aes(x = cyl, y = hwy)) |
(5) 如果使用 class 和 drv 绘制散点图,会发生什么情况?为什么这张图没什么用处?
ggplot(data = mpg) + | |
geom_point(mapping = aes(x = class, y =drv)) |
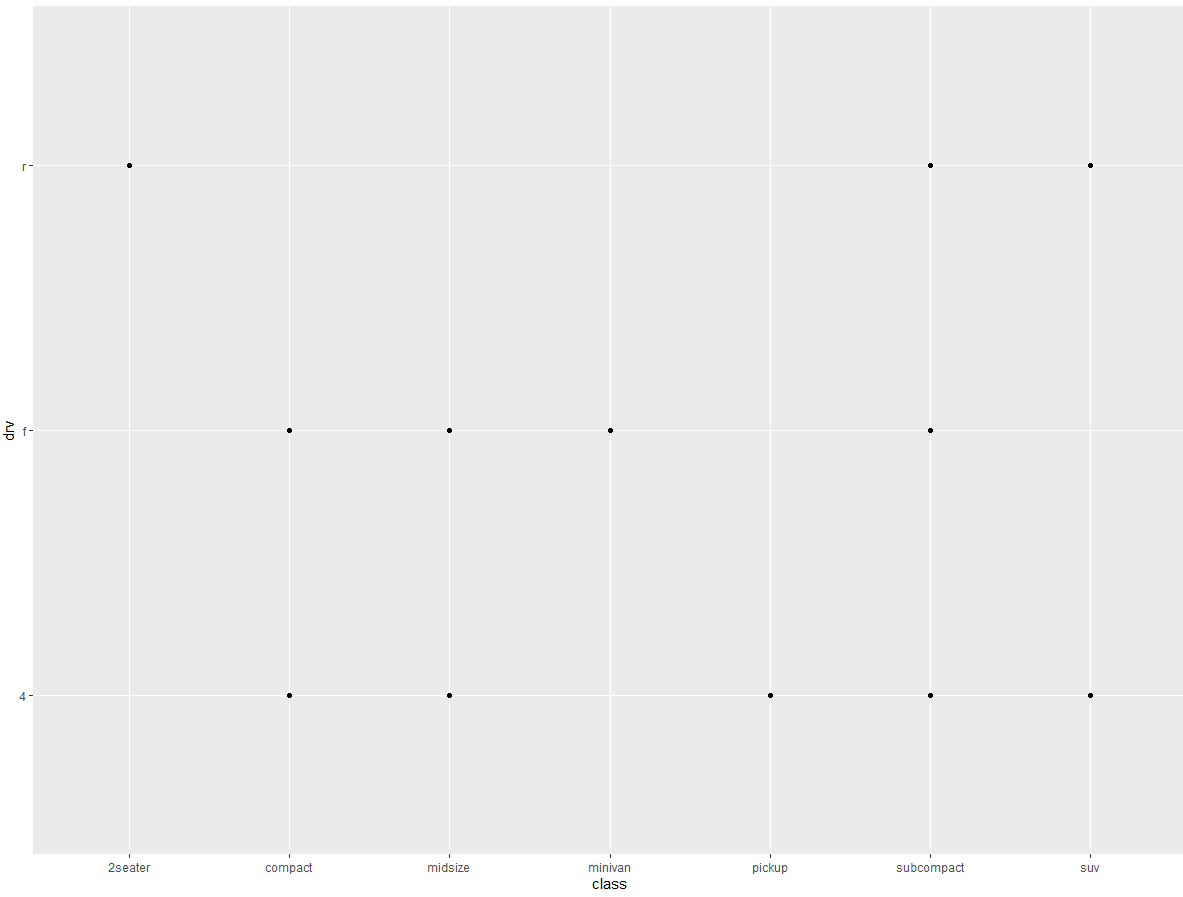
车的类型与驱动类型之间没有对应关系,或者说两者无法发生关系。
# 1.3 图形属性映射
The greatest value of a picture is when it forces us to notice what we never expected to see. —John Tukey
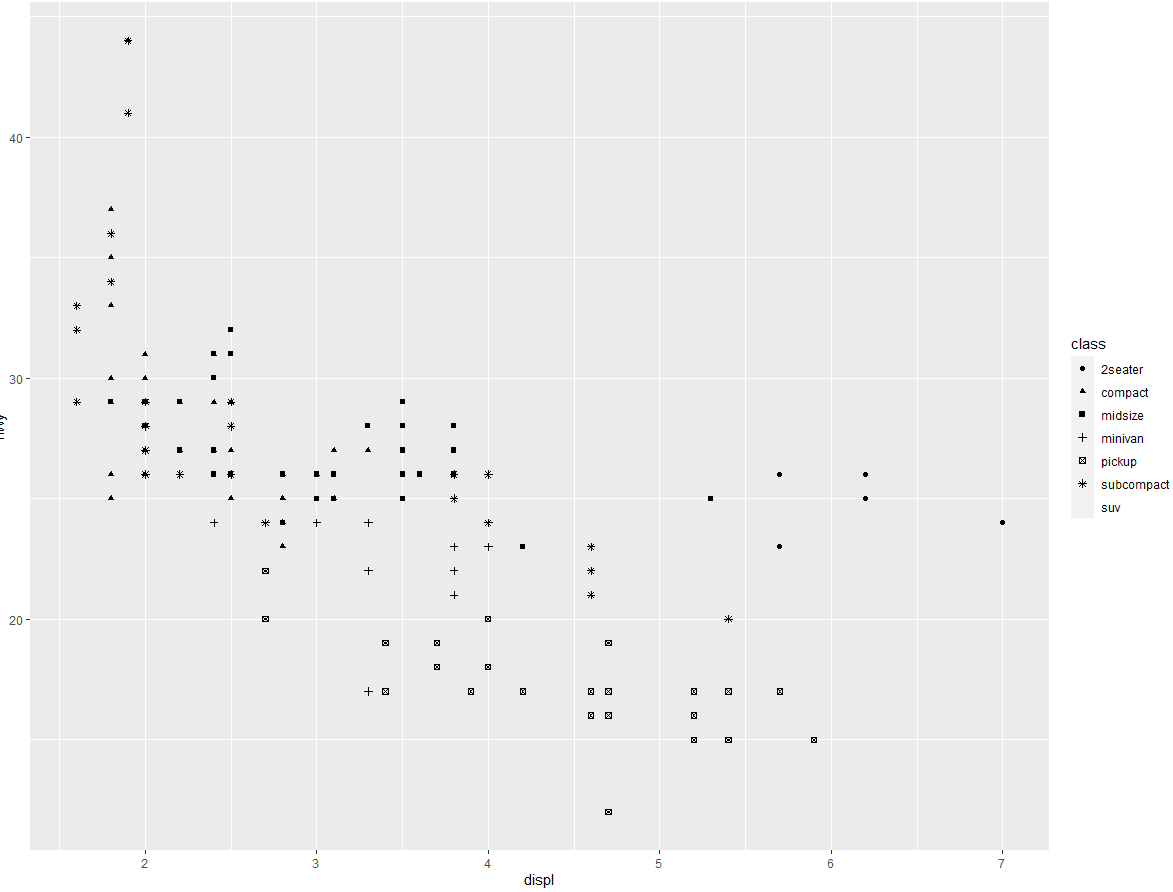
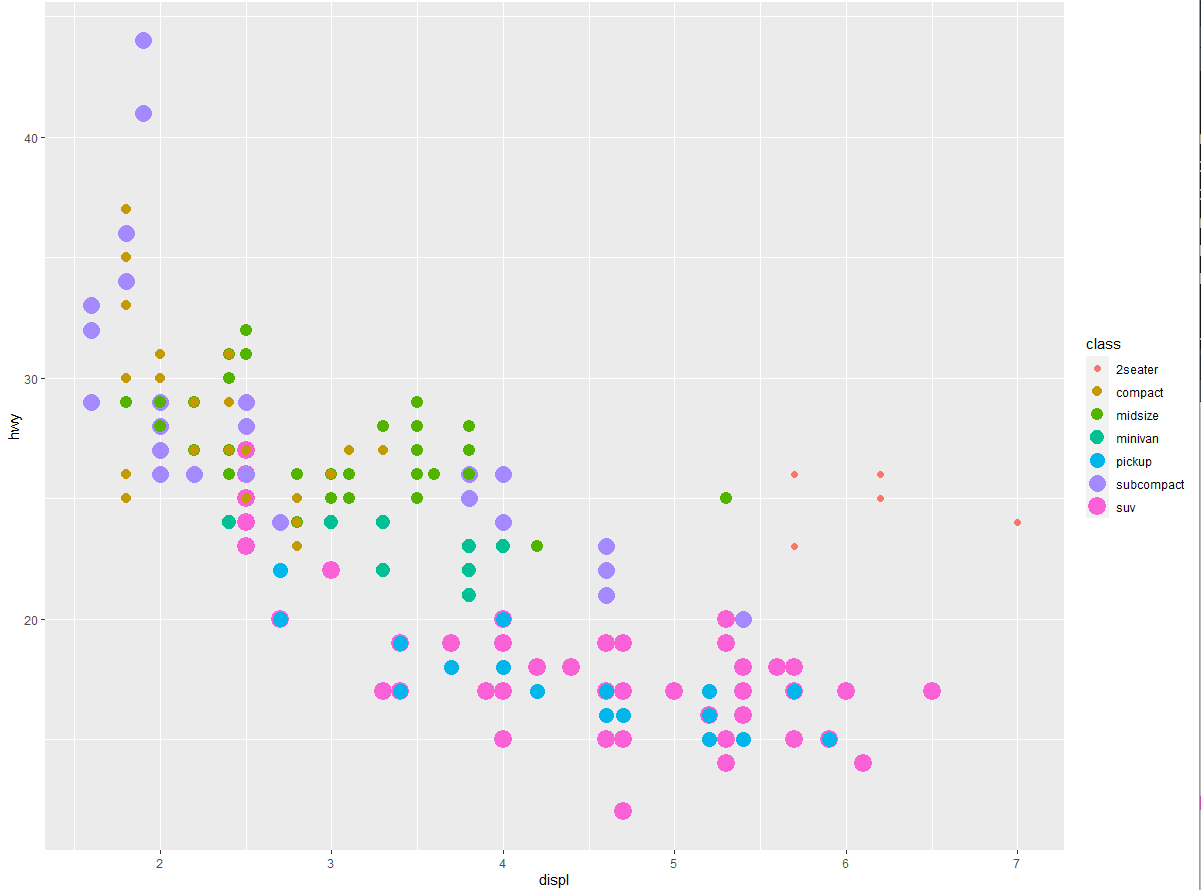
下图中有一组点(显示为红色)似乎位于线性趋势之外。这些汽车比预期具有更高的里程数。
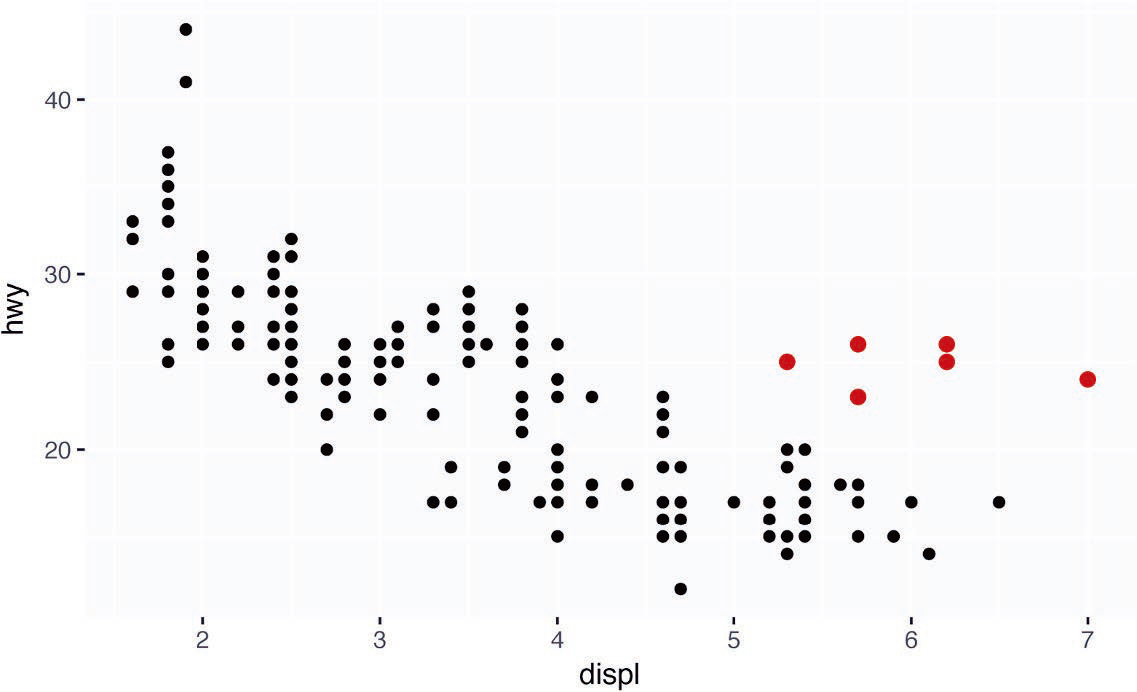
假设这些汽车是混合动力车。检验这种假设的一个方法是查看每辆汽车的 class 值。mpg 数据集中的 class 变量对汽车进行了分类,比如小型、中型和 SUV。如果那些离群点是混合动力车,那么它们应该分类为小型车,也可能是微型车(注意,这份数据是在混合动力车和 SUV 流行前收集的)。
可以向二维散点图中添加第三个变量,比如 class,方式是将它映射为图形属性。图形属性是图中对象的可视化属性,其中包括数据点的大小、形状和颜色。通过改变图形属性的值,可以用不同的方式来显示数据点(如下图所示)。因为已经使用 “value” 这个词来表示数据的值,所以下面使用 “level”(水平)这个词来表示图形属性的值。我们来改变一个点的大小、形状和颜色来反映不同属性。
通过将图中的图形属性映射为数据集中的变量,可以传达出数据的相关信息。例如,可以将点的颜色映射为变量 class,从而揭示每辆汽车的类型:
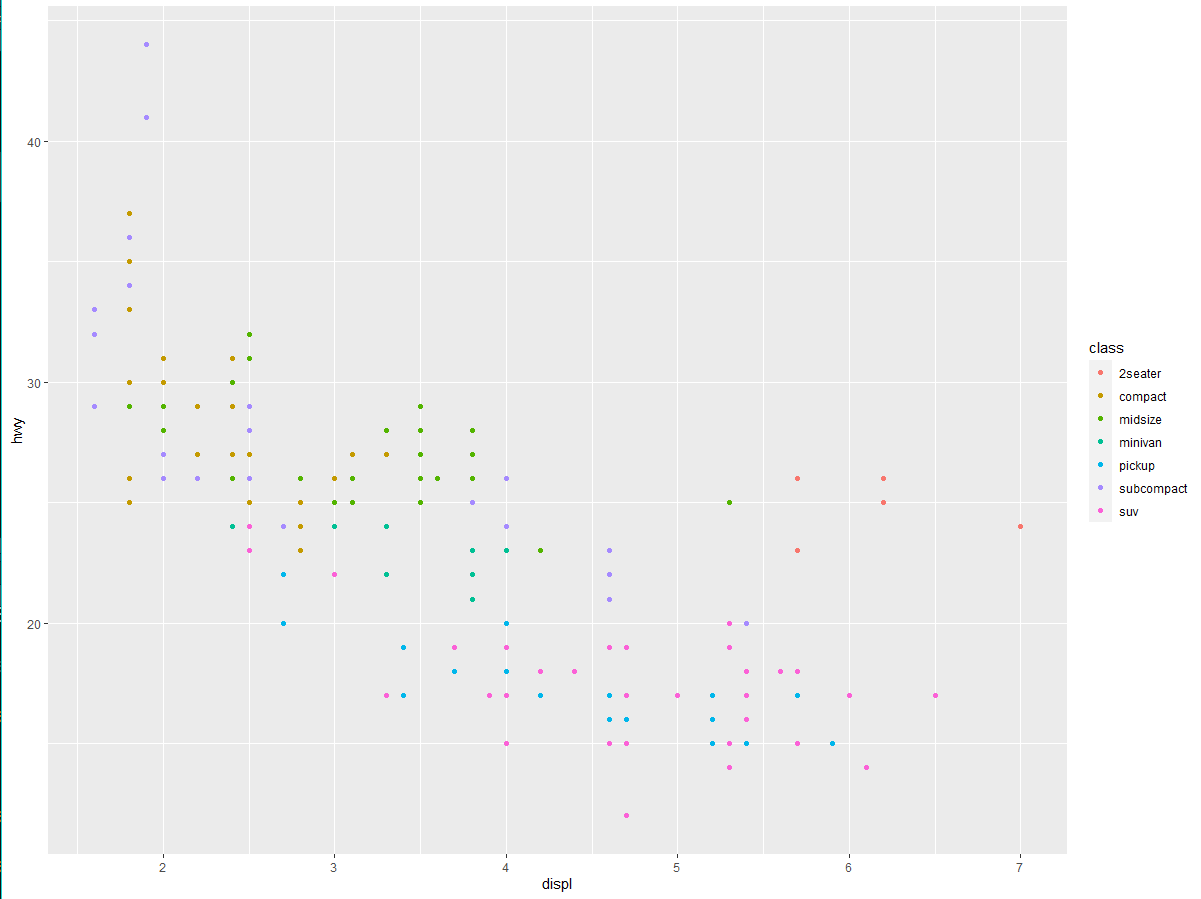
要想将图形属性映射为变量,需要在函数 aes () 中将图形属性名称和变量名称关联起来。ggplot2 会自动为每个变量值分配唯一的图形属性水平(本例中是唯一的颜色),这个过程称为标度变换。ggplot2 还会添加一个图例,以表示图形属性水平和变量值之间的对应关系。
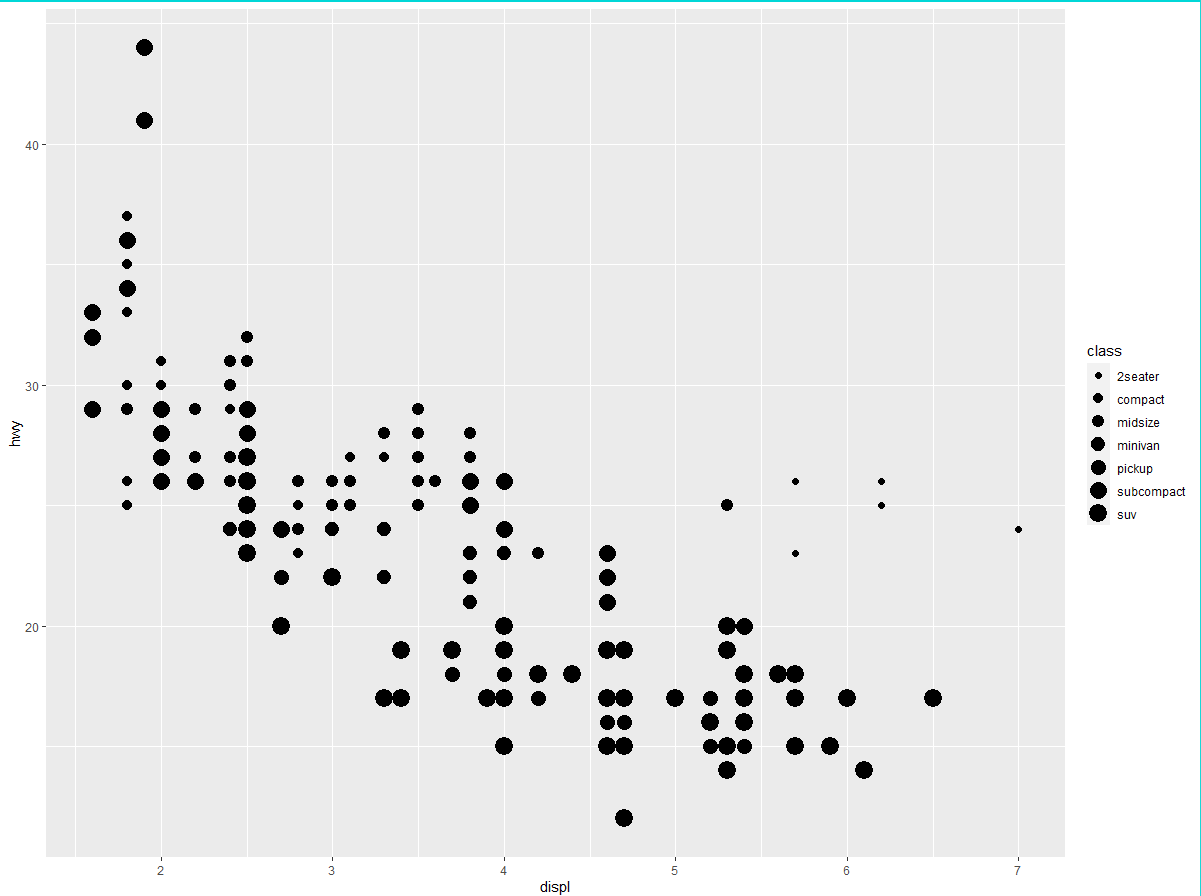
也可以用同样的方式将其映射为点的大小。在下面的示例中,每个点的实际大小表示其所属的类别。这里我们收到一条警告信息,因为将无序变量(class)映射为有序图形属性(size)可不是好主意。
ggplot(data = mpg) + | |
geom_point(mapping = aes(x = displ, y = hwy, size = class)) | |
Warning message: | |
Using size for a discrete variable is not advised. |
或者我们也可以将 class 映射为控制数据点透明度的 alpha 图形属性,还可以将其映射为点的形状。
# 上图 | |
ggplot (data = mpg) + | |
geom_point (mapping = aes (x = displ, y = hwy, alpha = class)) | |
# 下图 | |
ggplot (data = mpg) + | |
geom_point (mapping = aes (x = displ, y = hwy, shape = class)) |
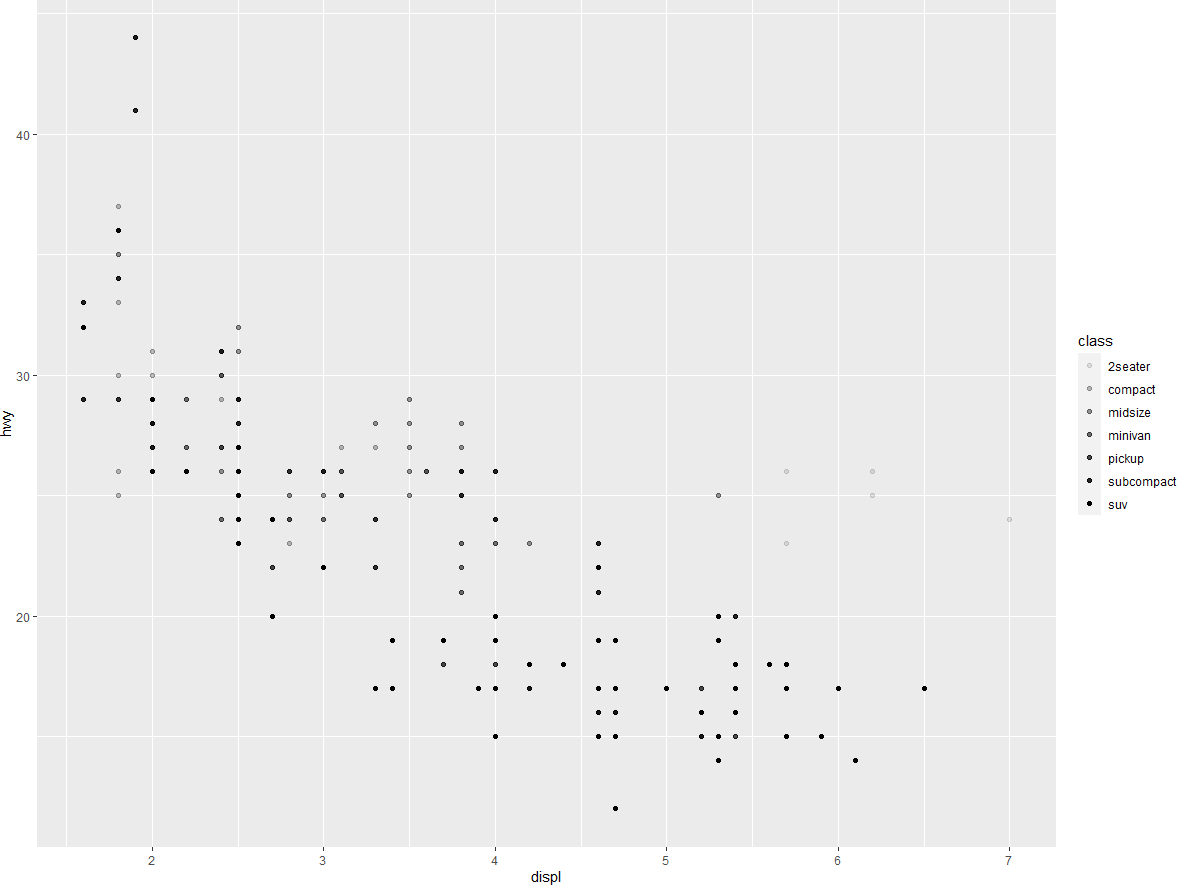
SUV 怎么了? ggplot2 只能同时使用 6 种形状。默认情况下,当使用这种图形属性时,多出的变量值将不会出现在图中。
一旦映射了图形属性,ggplot2 会处理好其余的事情。它会为图形属性选择一个合适的标度,并创建图例来表示图形属性水平和变量值之间的映射关系。ggplot2 不会为 x 和 y 这两个图形属性创建图例,而会创建带有刻度标记和标签的坐标轴。坐标轴就相当于图例,可以体现出位置和变量值之间的映射关系。
还可以手动为几何对象设置图形属性。例如,我们可以让图中的所有点都为蓝色:
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy), color = "blue")
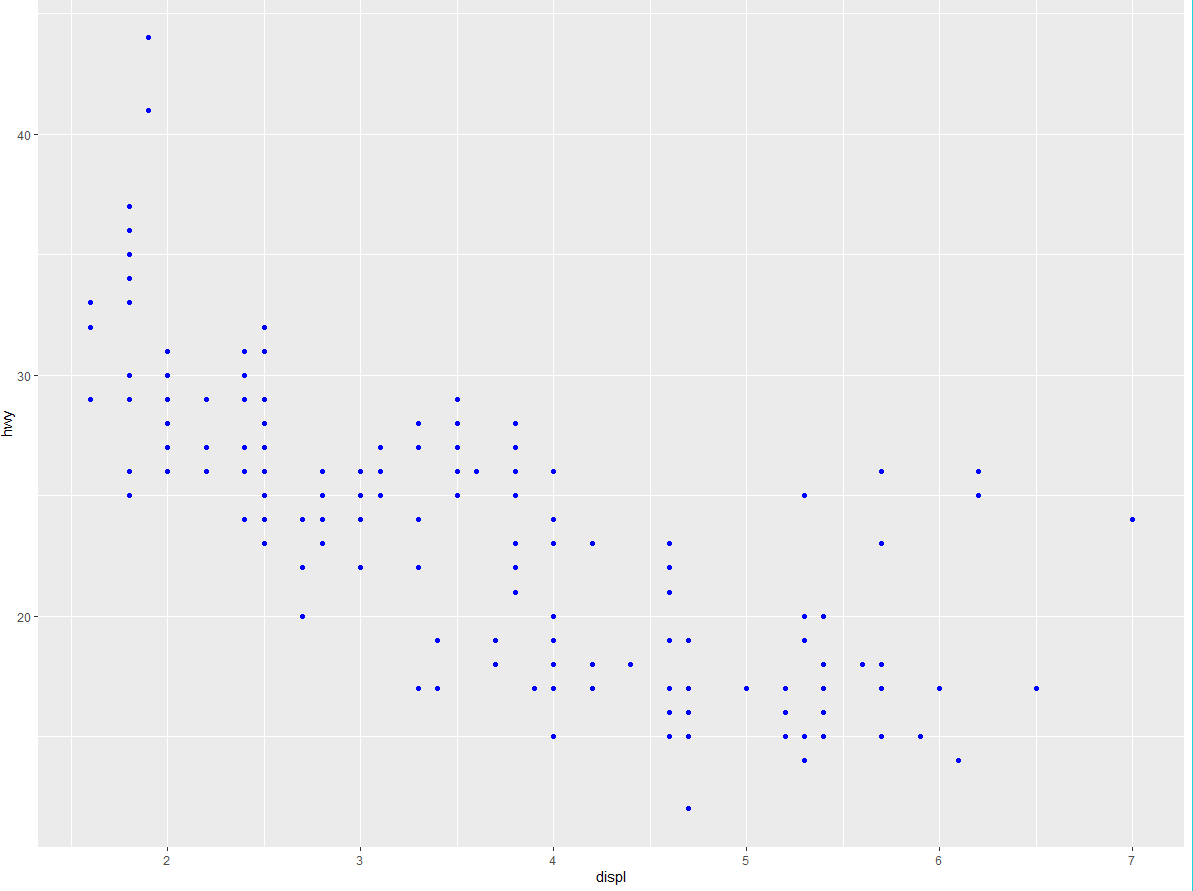
此时颜色不会传达关于变量的信息,只是改变图的外观。要想手动设置图形属性,需要按名称进行设置,将其作为几何对象函数的一个参数。这也就是说,需要在函数 aes () 的外部进行设置。此外,还需要为这个图形属性选择一个有意义的值。
・颜色名称是一个字符串。
・点的大小用毫米表示。
・点的形状是一个数值,如图 1-1 所示。有些形状相同,比如 0、15 和 22 都是正方形。
形状之间的区别在于 color 和 fill 这两个图形属性。空心形状(0~14)的边界颜色由 color 决定;实心形状(15~20)的填充颜色由 color 决定;填充形状(21~24)的边界颜色由 color 决定,填充颜色由 fill 决定。
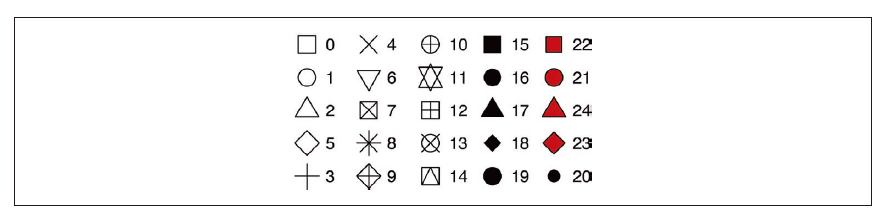
<center>
用数值进行标识的 R 的 25 种内置形状
</center>
# 练习
(1) 以下这段代码有什么错误?为什么点不是蓝色的?
ggplot(data = mpg) + | |
geom_point( | |
mapping = aes(x = displ, y = hwy, color = "blue")) |
color 在 mapping 的括号里面,成为了图形属性映射
(2) mpg 中的哪些变量是分类变量?哪些变量是连续变量?(提示:输入?mpg 来阅读这个数据集的文档。)当调用 mpg 时,如何才能看到这些信息?
在每一列的下方有 <chr> 和 < int > 两个属性,其中 < chr > 是分类变量,<int > 是连续变量
(3) 将一个连续变量映射为 color、size 和 shape。对分类变量和连续变量来说,这些图形属性的表现有什么不同?
ggplot(data = mpg) + | |
geom_point(mapping = aes(x = displ, y = hwy, color = hwy)) |
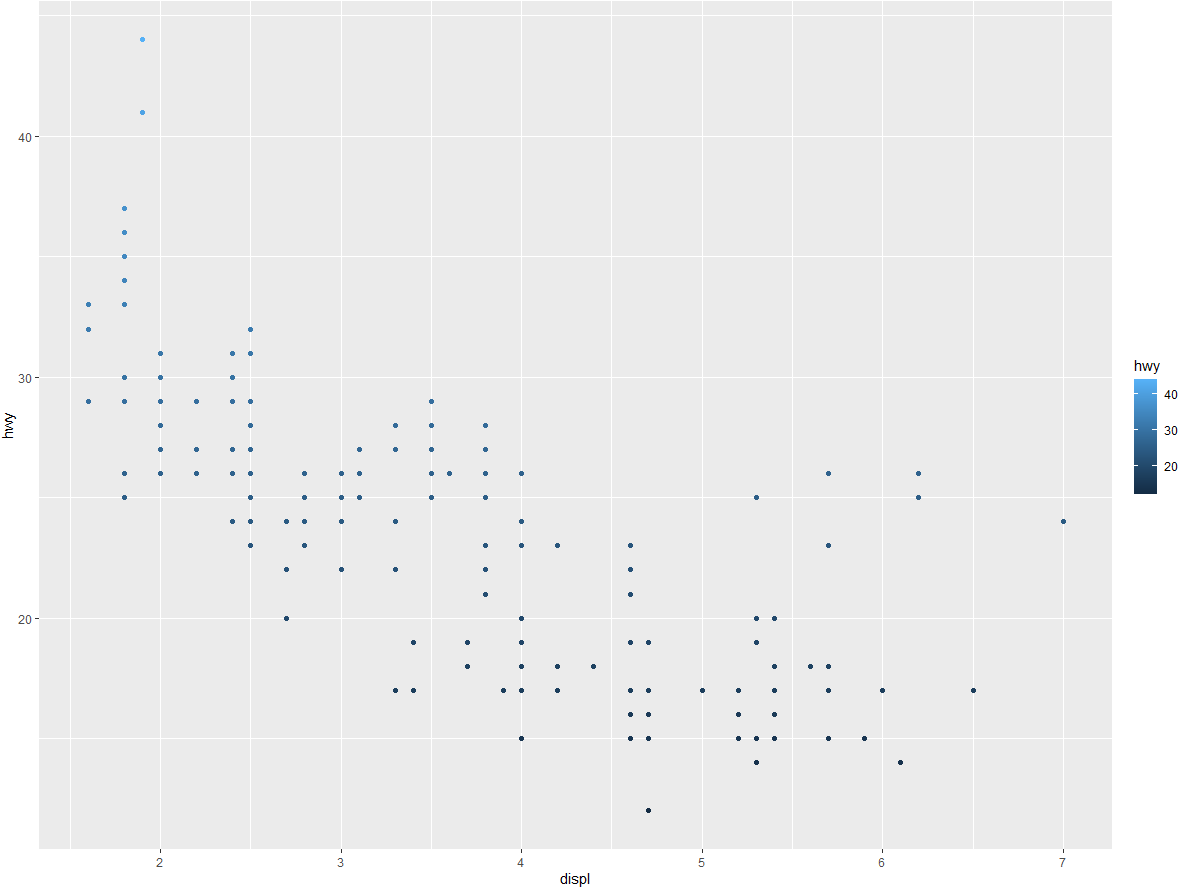
颜色是一个渐变色,大小也是渐变,形状会报错
(4) 如果将同一个变量映射为多个图形属性,会发生什么情况?
两种属性会结合,例如颜色和大小
ggplot(data = mpg) + | |
geom_point(mapping = aes(x = displ, y = hwy, size = class, color=class)) |
(5) stroke 这个图形属性的作用是什么?它适用于哪些形状?(提示:使用?geom_point 命令。)
改变形状的边框的大小
(6) 如果将图形属性映射为非变量名对象,比如 aes (color = displ < 5),会发生什么情况?
Error: geom_point requires the following missing aesthetics: x and y
# 1.4 常见问题
当开始运行 R 代码时,你很可能会遇到问题。不用担心,每个人都会遇到问题。首先,将你需要运行的代码与书中的代码进行仔细对比。R 极其挑剔,即使一个字母放错了位置,也可能会造成问题。确保每个 (都有一个) 与之匹配,并且每个 "后面都跟着另一个"。有时运行了代码却什么也没有发生。检查一下控制台左侧:如果有一个 + 号,那么说明 R 认为你没有输入完整的表达式,正在等待你完成输入。这种情况下,按 Esc 键中止当前执行的命令就可以重新开始。
创建 ggplot2 图形时的一个常见问题是将 + 号放错了位置:+ 必须放在一行代码的末尾,而不是开头。
# 1.5 分面
添加额外变量的一种方法是使用图形属性。另一种方法是将图分割成多个分面,即可以显示数据子集的子图。这种方法特别适合添加分类变量。
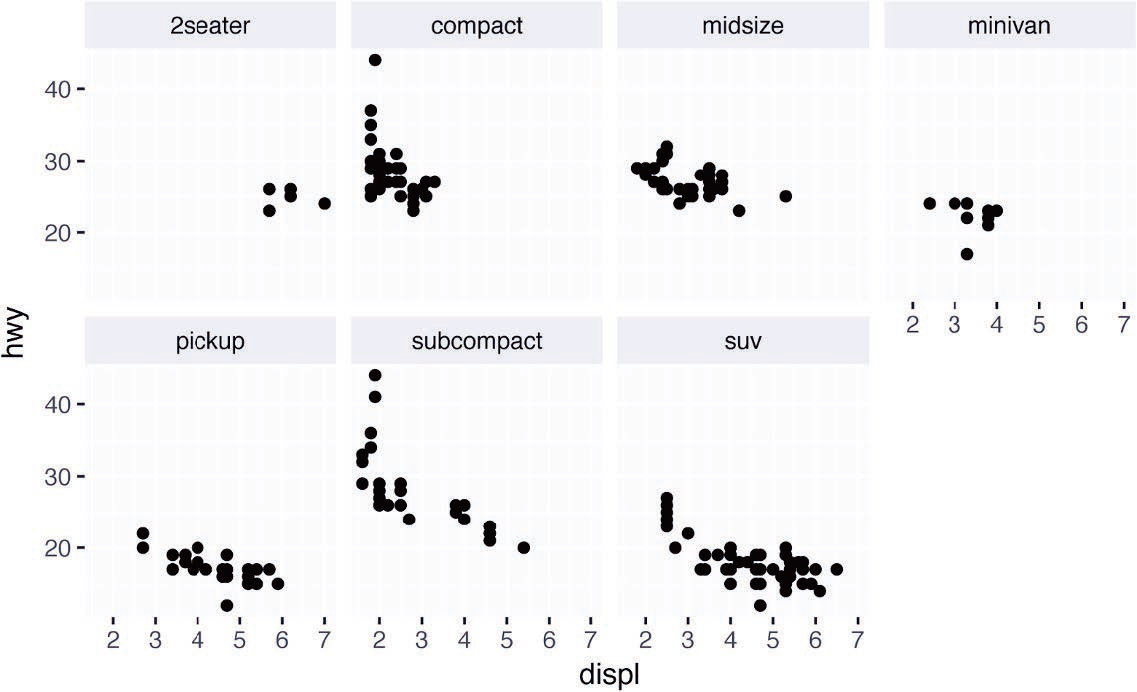
要想通过单个变量对图进行分面,可以使用函数 facet_wrap ()。其第一个参数是一个公式,创建公式的方式是在~符号后面加一个变量名(这里所说的 “公式” 是 R 中的一种数据结构,不是数学意义上的公式)。传递给 facet_wrap () 的变量应该是离散型的。
ggplot(data = mpg) + | |
geom_point(mapping = aes(x = displ, y = hwy),stroke=1.5) + | |
facet_wrap(~ class, nrow = 2) |
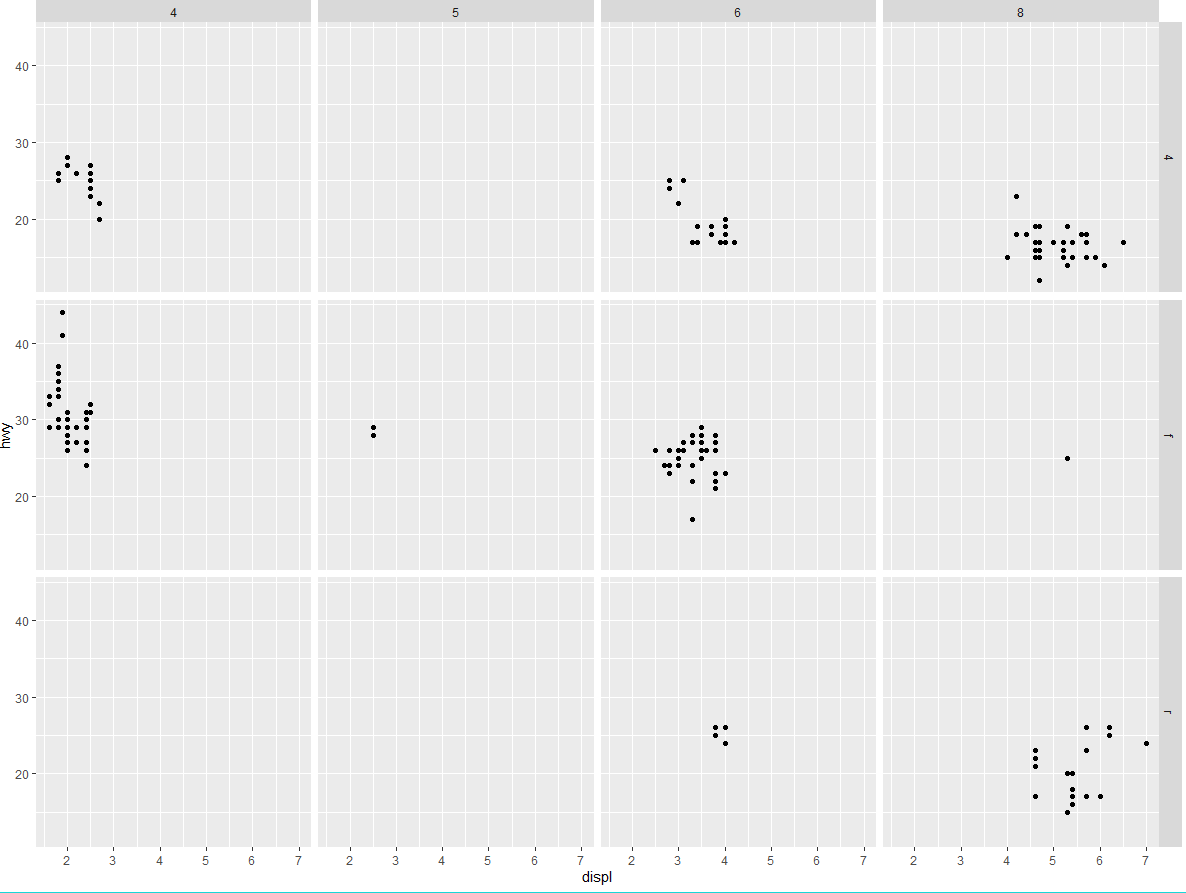
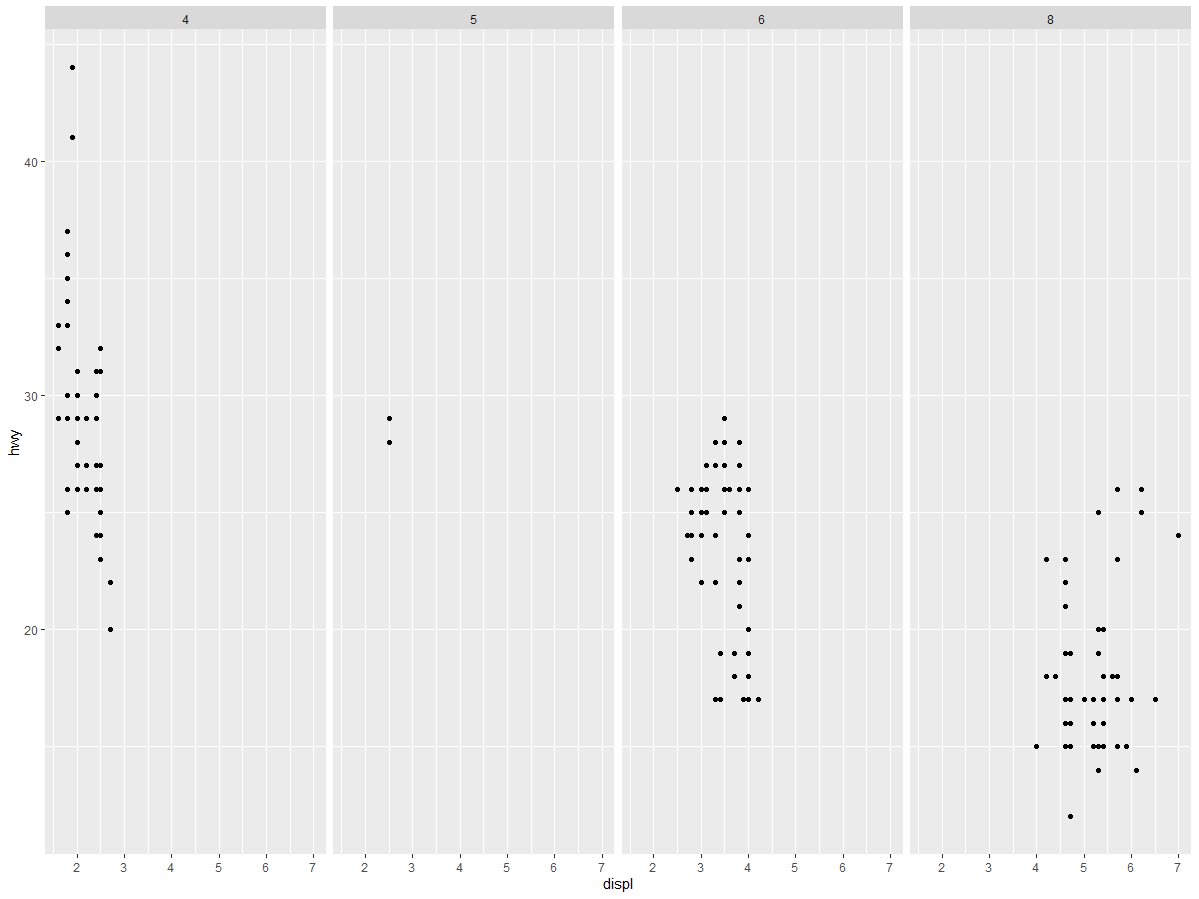
要想通过两个变量对图进行分面,需要在绘图命令中加入函数 facet_grid ()。这个函数的第一个参数也是一个公式,但该公式包含由~隔开的两个变量名。
ggplot(data = mpg) + | |
geom_point(mapping = aes(x = displ, y = hwy)) + | |
facet_grid(drv ~ cyl) |
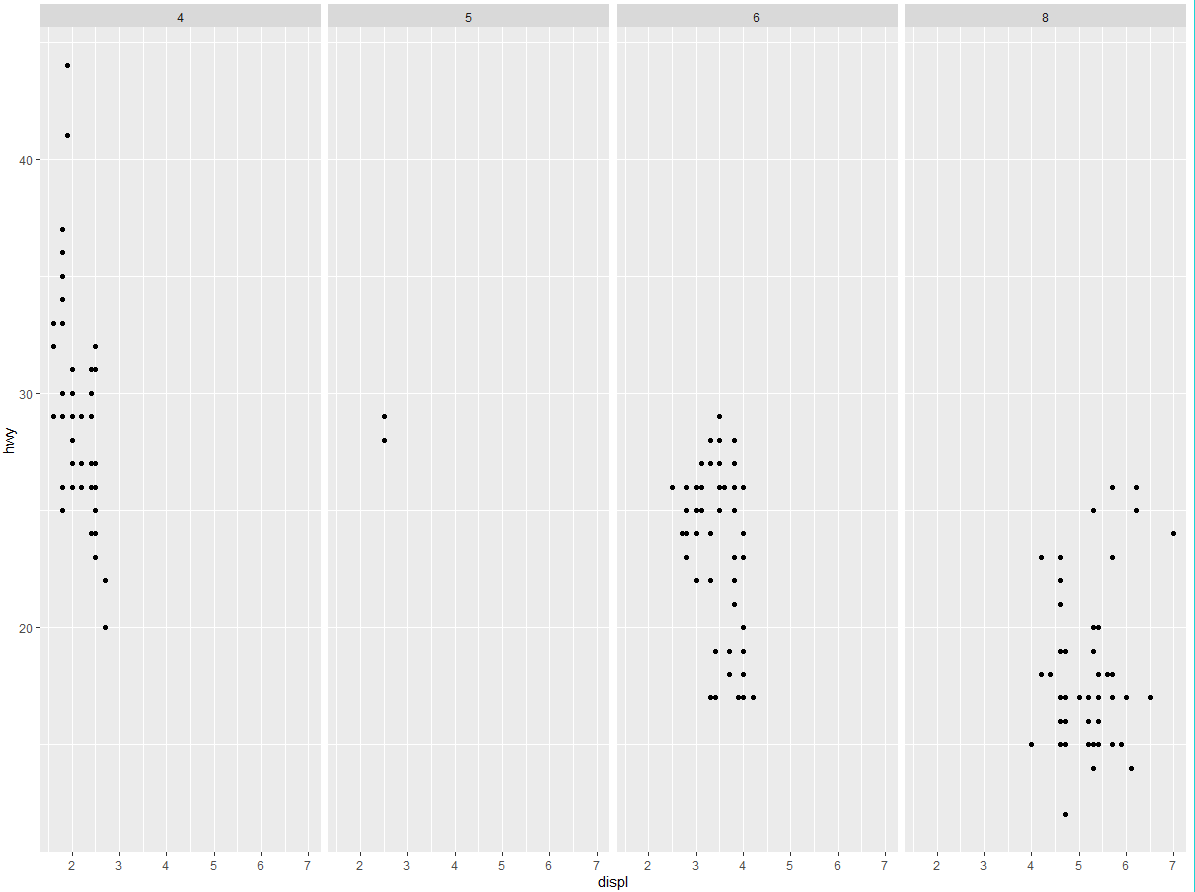
如果不想在行或列的维度进行分面,你可以使用。来代替变量名,例如 + facet_grid (. ~cyl)。
# 练习
(1) 如果使用连续变量进行分面,会发生什么情况?
ggplot(data = mpg) + | |
geom_point(mapping = aes(x = displ, y = hwy)) + | |
facet_grid(~ cty) |
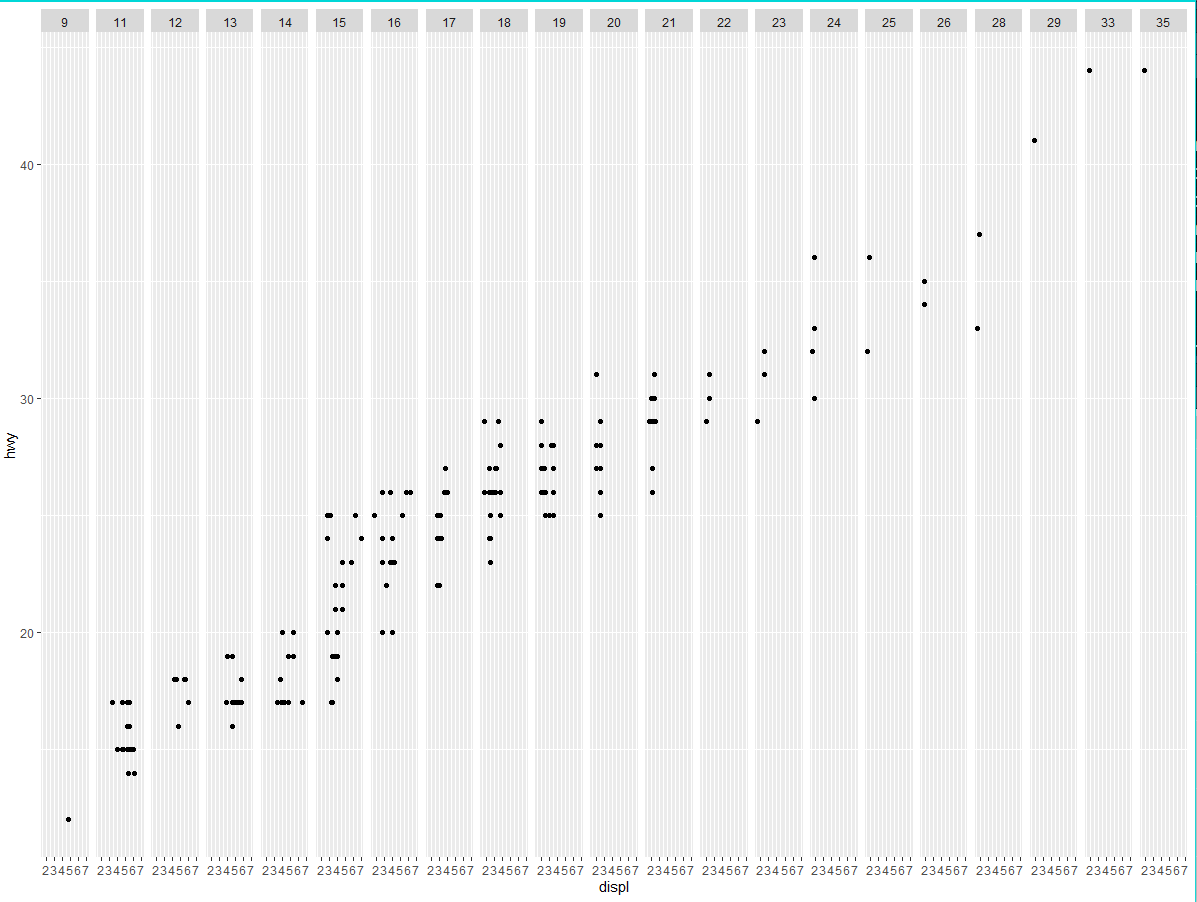
(2) 在使用 facet_grid (drv ~ cyl) 生成的图中,空白单元的意义是什么?它们和以下代码生成的图有什么关系?
虽然空白单元没有数据,但也代表了一种组合
ggplot(data = mpg) + | |
geom_point(mapping = aes(x = drv, y = cyl)) |
这张图生成的是没有意义的图,每个点代表每种组合,facet_grid (drv ~ cyl) 生成的图则将每个组合中 displ 和 hwy 之间的关系表现了出来。
(3) 以下代码会绘制出什么图? . 的作用是什么?
ggplot(data = mpg) + | |
geom_point(mapping = aes(x = displ, y = hwy)) + | |
facet_grid(drv ~ .) |
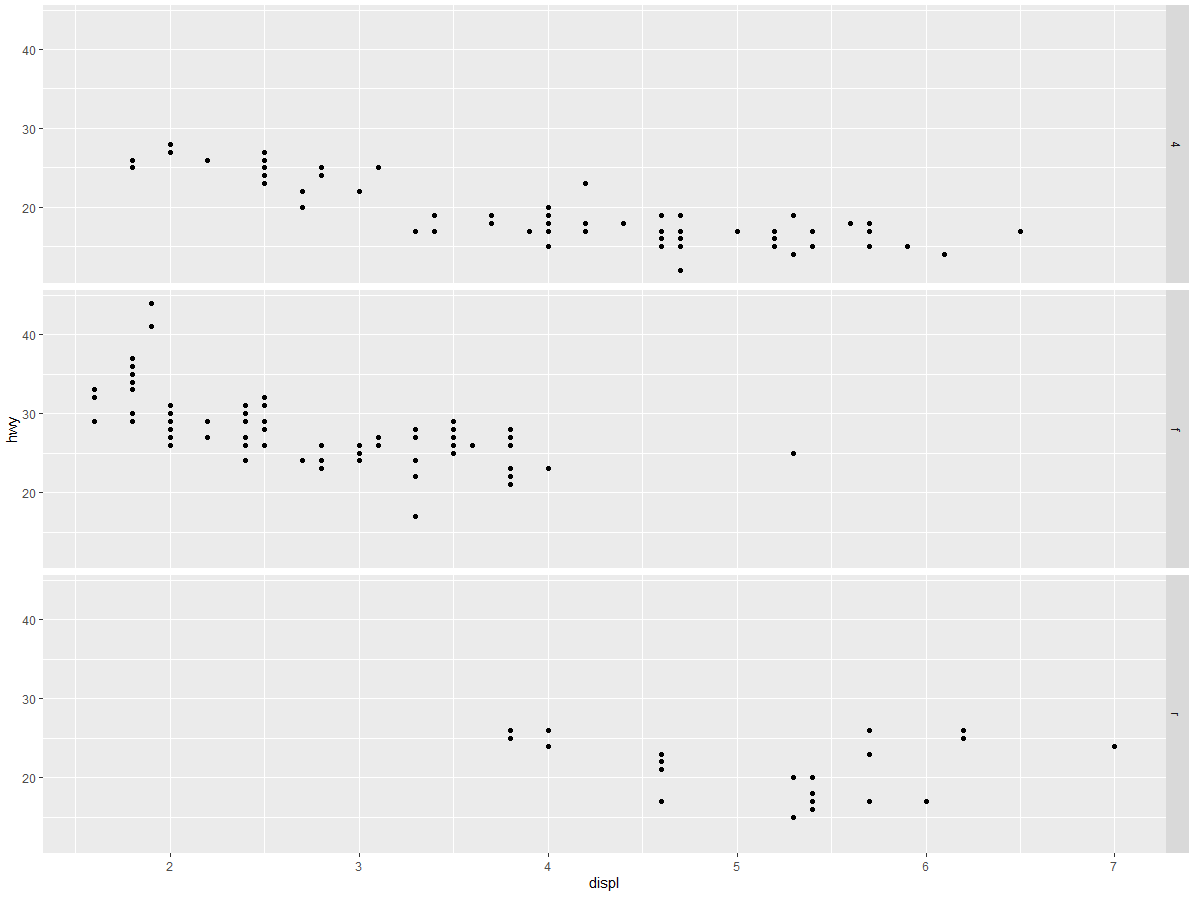
ggplot(data = mpg) + | |
geom_point(mapping = aes(x = displ, y = hwy)) + | |
facet_grid(. ~ cyl) |
. 的作用决定了分布方向,如果前面出现、纵向分布,反之为横向分布
(4) 查看本节的第一个分面图:
ggplot(data = mpg) + | |
geom_point(mapping = aes(x = displ, y = hwy)) + | |
facet_wrap(~ class, nrow = 2) |
与使用图形属性相比,使用分面的优势和劣势分别是什么?如果有一个更大的数据集,
你将如何权衡这两种方法的优劣?
使用分面能更好的体现出每个类别 displ 与 hwy 的关系,但是没办法比较不同类别之间的区别
使用属性能更好的体现整体的关系,但是个体差异不明显
# 1.6 几何对象
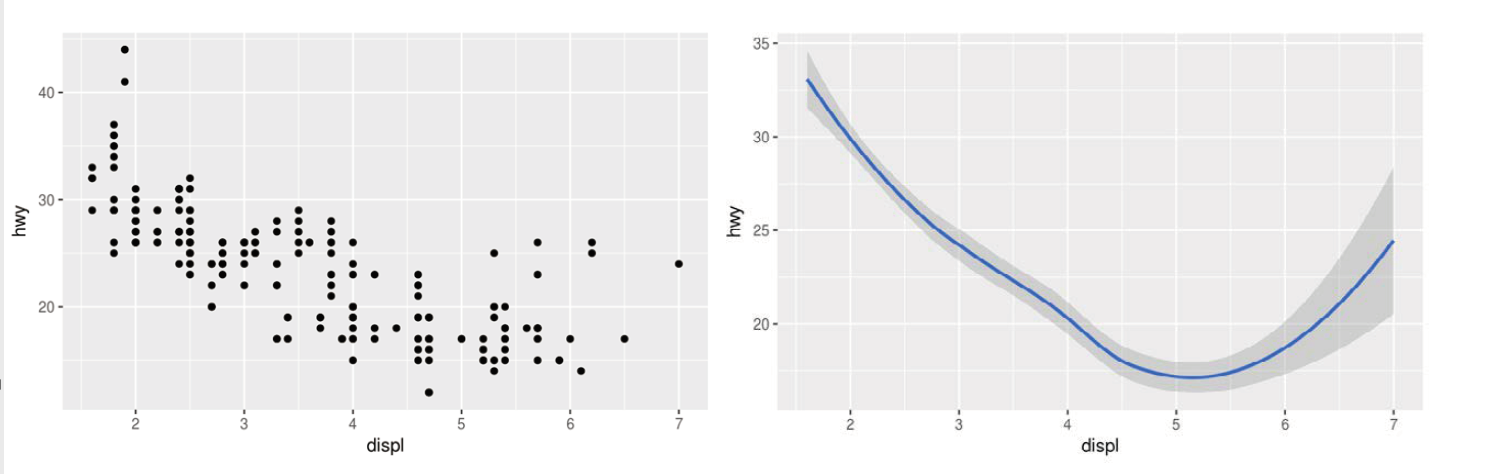
两张图有同样的 x 变量和 y 变量,而且描述的是同样的数据。但这两张图并不一样,它们各自使用不同的可视化对象来表示数据。在 ggplot2 语法中,我们称它们使用了不同的几何对象。
几何对象是图中用来表示数据的几何图形对象。我们经常根据图中使用的几何对象类型来描述相应的图。例如,条形图使用了条形几何对象,折线图使用了直线几何对象,箱线图使用了矩形和直线几何对象。散点图打破了这种趋势,它们使用点几何对象。如上面的两幅图所示,我们可以使用不同的几何对象来表示同样的数据。左侧的图使用了点几何对象,右侧的图使用了平滑曲线几何对象,以一条平滑曲线来拟合数据。要想改变图中的几何对象,需要修改添加在 ggplot () 函数中的几何对象函数。举例来说,要想绘制出上图,你可以使用以下代码:
# 左图 | |
ggplot (data = mpg) + | |
geom_point (mapping = aes (x = displ, y = hwy)) | |
# 右图 | |
ggplot (data = mpg) + | |
geom_smooth (mapping = aes (x = displ, y = hwy)) |
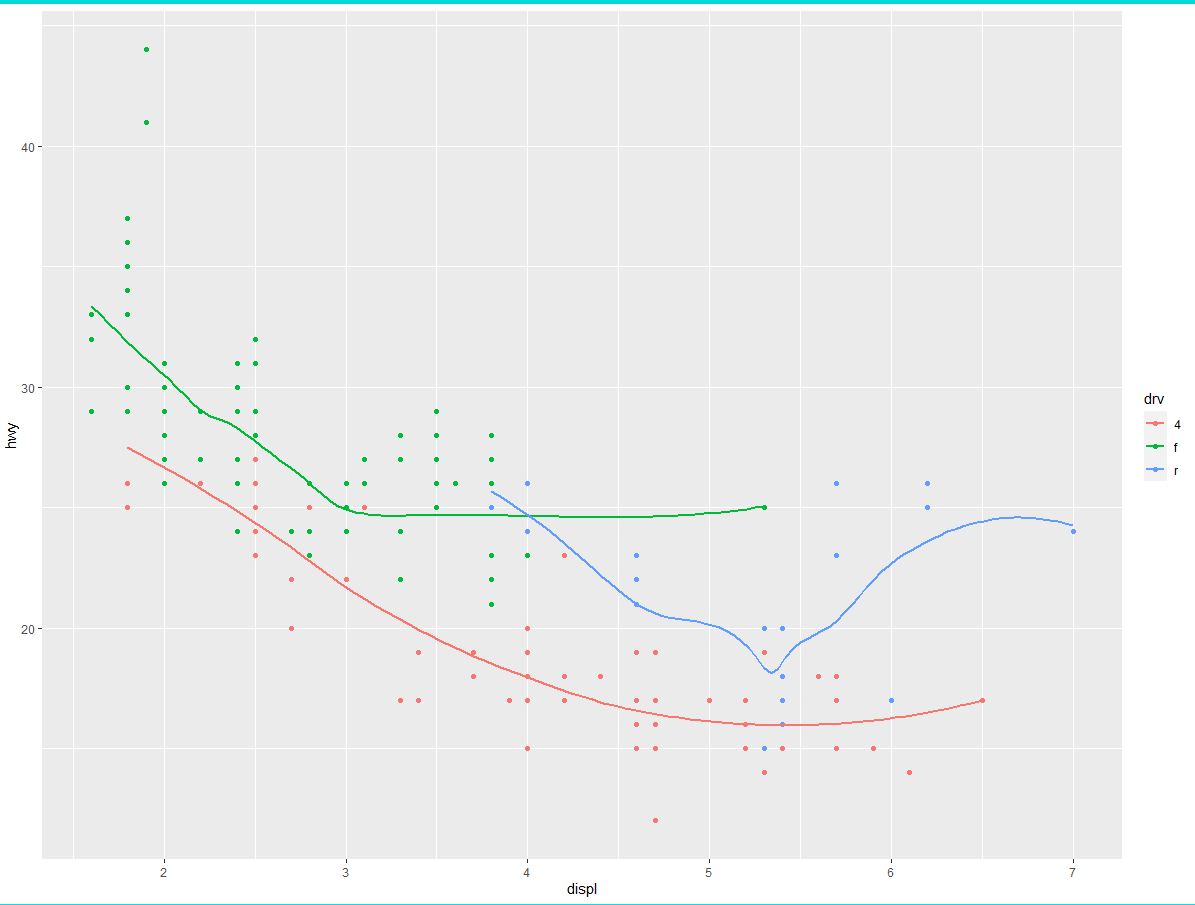
ggplot2 中的每个几何对象函数都有一个 mapping 参数。但是,不是每种图形属性都适合每种几何对象。你可以设置点的形状,但不能设置线的 “形状”,而可以设置线的线型。geom_smooth () 函数可以按照不同的线型绘制出不同的曲线,每条曲线对应映射到线型的变量的一个唯一值:
ggplot(data = mpg) + | |
geom_smooth(mapping = aes(x = displ, y = hwy, linetype = drv)) |
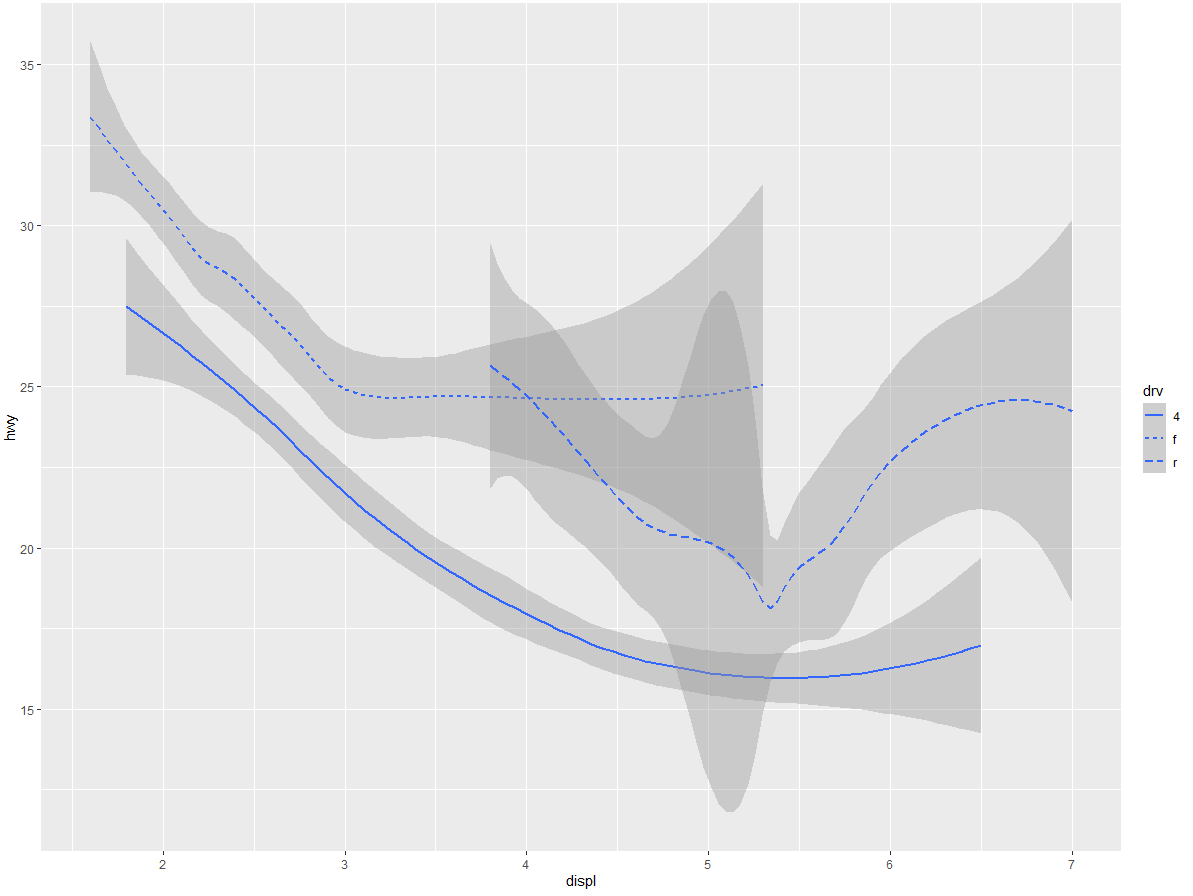
根据表示汽车驱动系统的 drv 变量的值,这里的 geom_smooth () 函数分别用 3 条曲线来表示汽车。一条线表示 drv 值为 4 的所有汽车,一条线表示 drv 值为 f 的所有汽车,另一条线表示 drv 值为 r 的所有汽车。其中 4 表示四轮驱动,f 表示前轮驱动,r 表示后轮驱动。如果你觉得这有些难以理解,我们可以将这些曲线覆盖在原始数据上,并按照 drv 值对所有的点和线进行着色,这样你就能看得更清楚一些了。
要想在同一张图中显示多个几何对象,可以向 ggplot () 函数中添加多个几何对象函数:
ggplot(data = mpg) + | |
geom_point(mapping = aes(x = displ, y = hwy)) + | |
geom_smooth(mapping = aes(x = displ, y = hwy)) |
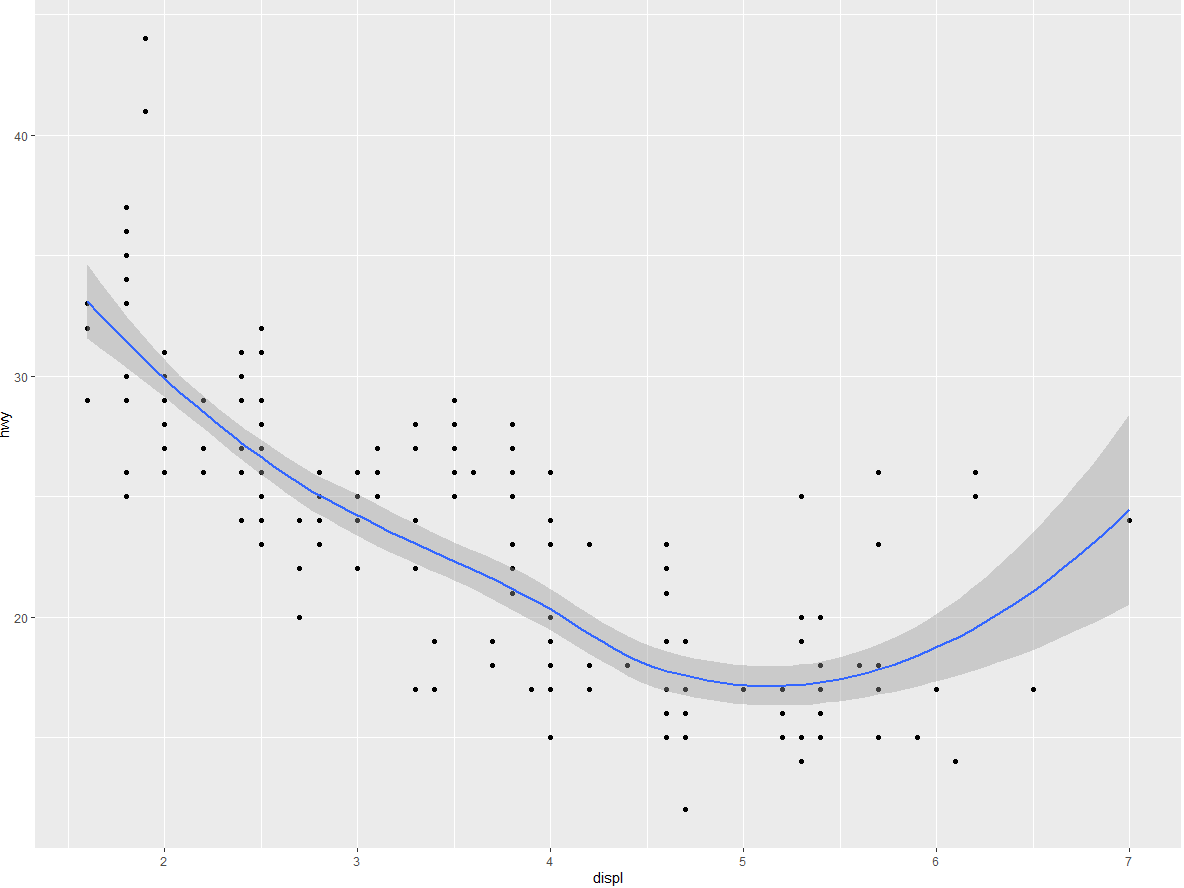
但是,这样代码就产生了一些重复。假如你想将 y 轴上的变量从 hwy 改成 cty,那么就要在两个地方修改这个变量,但你或许会漏掉一处。避免这种重复的方法是将一组映射传递给 ggplot () 函数。ggplot2 会将这些映射作为全局映射应用到图中的每个几何对象中。
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) + | |
geom_point() + | |
geom_smooth() |
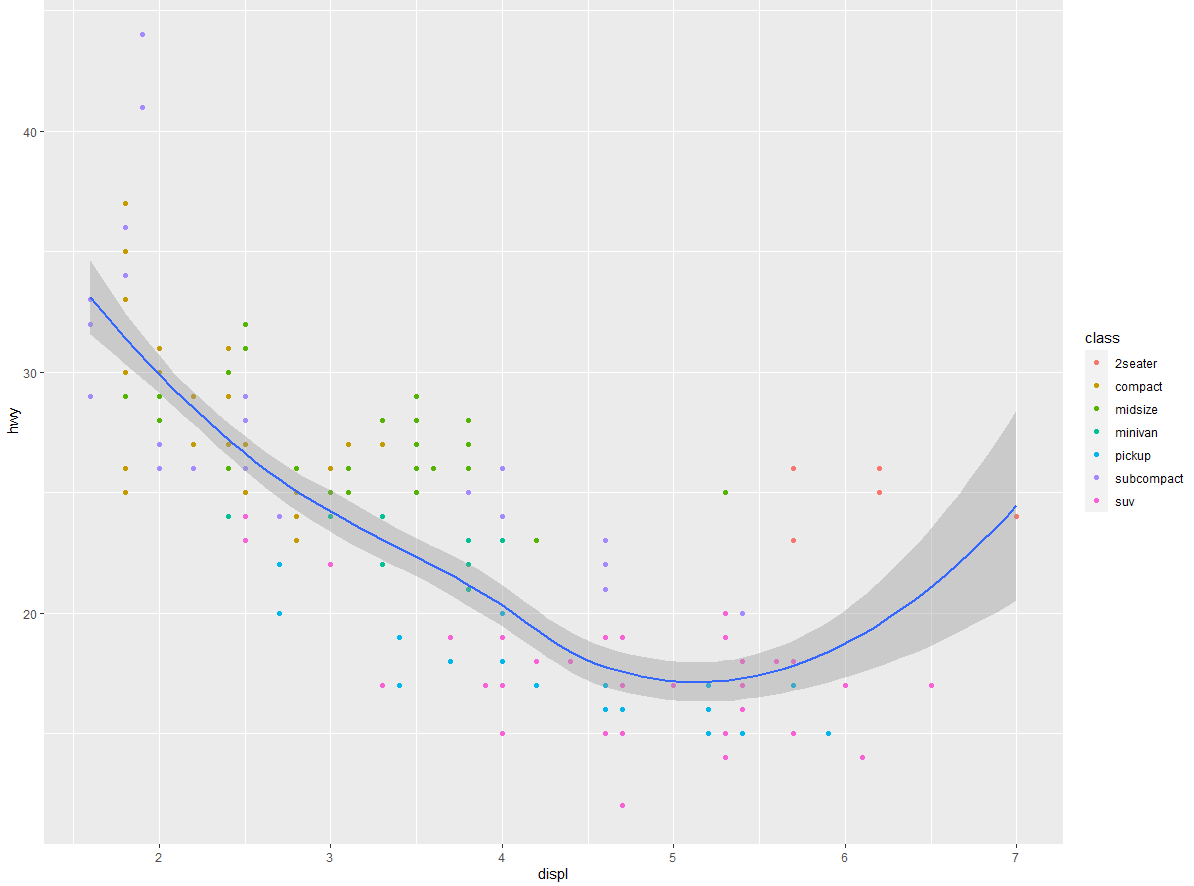
如果将映射放在几何对象函数中,那么 ggplot2 会将其看作这个图层的局部映射,它将使用这些映射扩展或覆盖全局映射,但仅对该图层有效。这样一来,我们就可以在不同的图层中显示不同的图形属性:
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) + | |
geom_point(mapping = aes(color = class)) + | |
geom_smooth() |
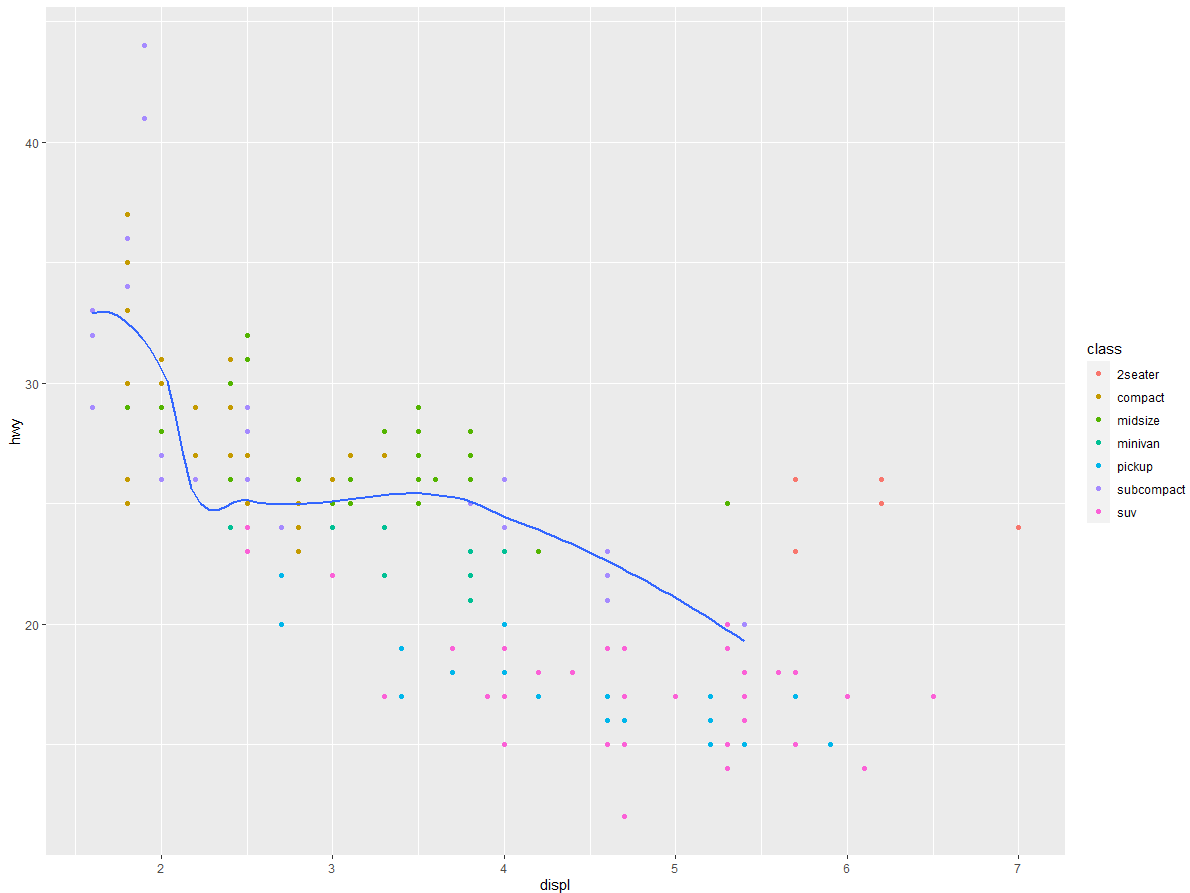
同理,你也可以为不同的图层指定不同的数据。下图中的平滑曲线表示的只是 mpg 数据集的一个子集,即微型车。geom_smooth () 函数中的局部数据参数覆盖了 ggplot () 函数中的全局数据参数,当然仅对这个图层有效:
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) + | |
geom_point(mapping = aes(color = class)) + | |
geom_smooth( | |
data = filter(mpg, class == "subcompact"), | |
se = FALSE | |
) |
# 练习
(1) 在绘制折线图、箱线图、直方图和分区图时,应该分别使用哪种几何对象?
折线图使用了直线几何对象,箱线图使用了矩形和直线几何图像、直方图使用了使用了矩形几何对象
(2) 在脑海中运行以下代码,并预测会有何种输出。接着在 R 中运行代码,并检查你的预测是否正确。
ggplot( | |
data = mpg, | |
mapping = aes(x = displ, y = hwy, color = drv) | |
) + | |
geom_point() + | |
geom_smooth(se = FALSE) |
(3) show.legend = FALSE 的作用是什么?删除它会发生什么情况?你觉得我为什么要在本章前面的示例中使用这句代码?
sohw.legend=FLASE 去掉图例
(4) geom_smooth () 函数中的 se 参数的作用是什么?
se 如果设定为 TRUE,则会为曲线设定置信区间,FLASE 则没有置信区间
(6) 自己编写 R 代码来生成以下各图。
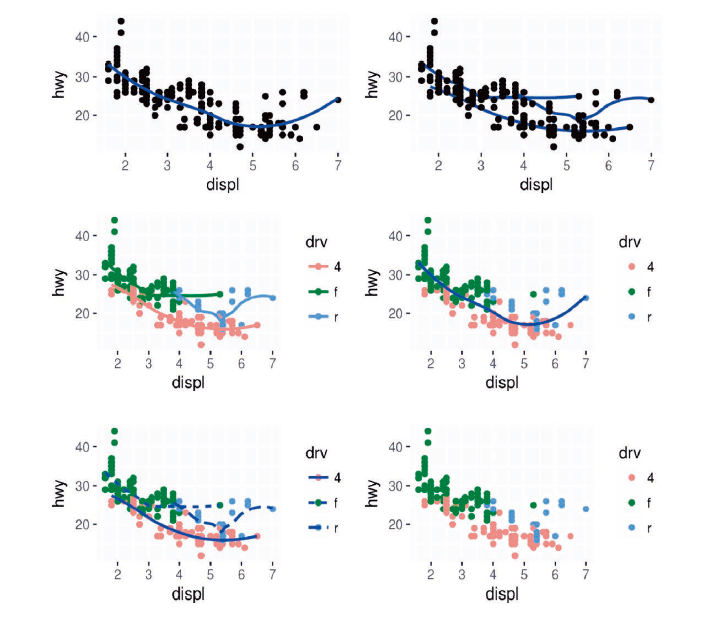
#######1 | |
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) + | |
geom_point() + | |
geom_smooth(se=FALSE) | |
#######2 | |
ggplot() + | |
geom_point( | |
data = mpg, | |
mapping = aes(x = displ, y = hwy) | |
) + | |
geom_smooth( | |
data = mpg, | |
mapping = aes(x = displ, y = hwy,group=drv),se=FALSE) | |
#######3 | |
ggplot(data = mpg, mapping = aes(x = displ, y = hwy,color=drv)) + | |
geom_point() + | |
geom_smooth(se = FALSE) | |
#######4 | |
ggplot() + | |
geom_point( | |
data = mpg, | |
mapping = aes(x = displ, y = hwy,color=drv) | |
) + | |
geom_smooth( | |
data = mpg, | |
mapping = aes(x = displ, y = hwy),se=FALSE) | |
######5 | |
ggplot() + | |
geom_point( | |
data = mpg, | |
mapping = aes(x = displ, y = hwy,color=drv) | |
) + | |
geom_smooth( | |
data = mpg, | |
mapping = aes(x = displ, y = hwy,linetype=drv),se=FALSE) | |
######6 | |
ggplot() + | |
geom_point( | |
data = mpg, | |
mapping = aes(x = displ, y = hwy,color=drv)) |
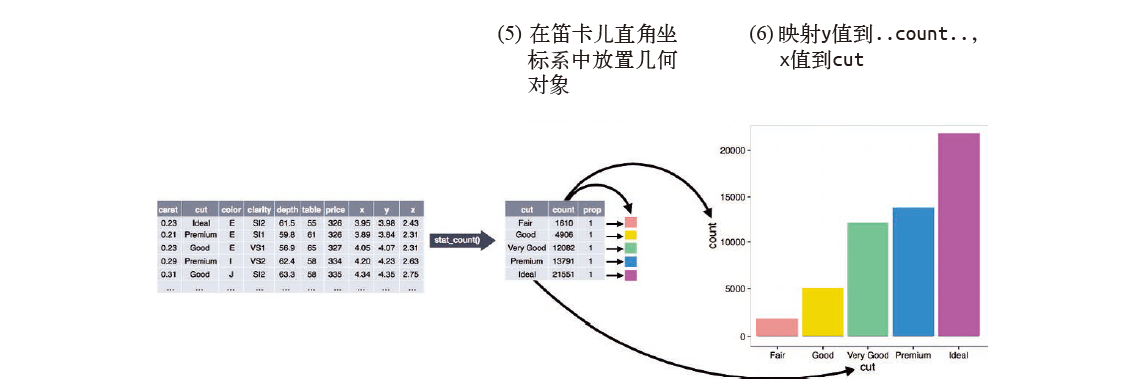
# 1.7 统计变换
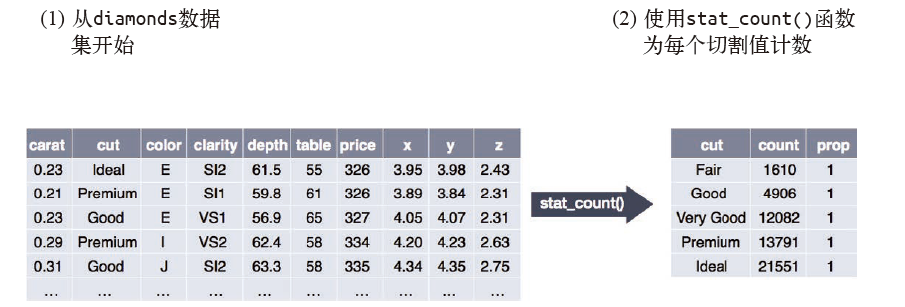
接下来我们看一下条形图。条形图虽然简单,但很有意思,因为它可以揭示出图形中的一些微妙信息。我们看一下用 geom_bar () 函数就可以绘制的基本条形图。下面的条形图显示了 diamonds 数据集中按照 cut 变量分组的各种钻石的总数量。diamonds 数据集是 ggplot2 的内置数据集,包含大约 54 000 颗钻石的信息,每颗钻石具有 price、carat、color、clarity 和 cut 变量。条形图显示,高质量切割钻石的数量要比低质量切割钻石的数量多:
ggplot(data = diamonds) + | |
geom_bar(mapping = aes(x = cut)) |
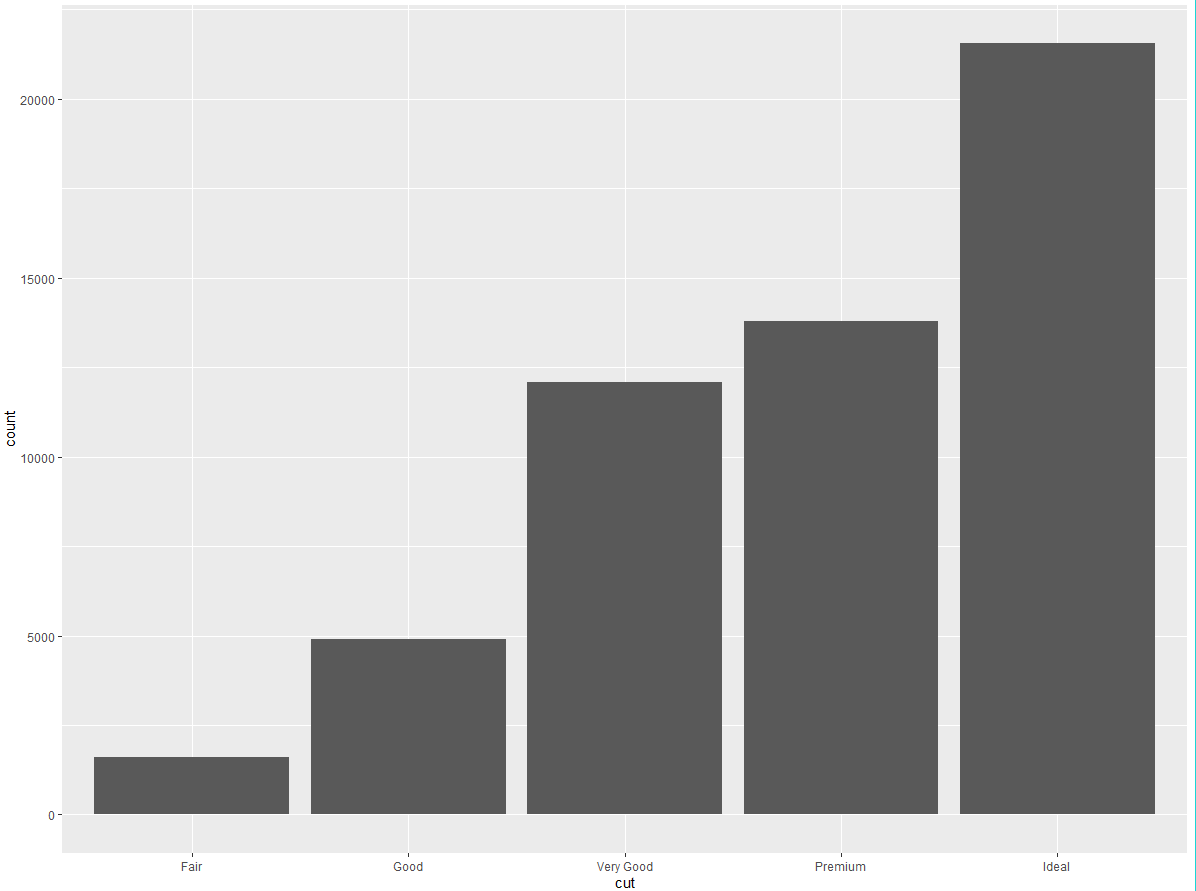
条形图 x 轴显示的是 cut,这是 diamonds 数据集中的一个变量。y 轴显示的是 count,但 count 不是 diamonds 中的变量!那么 count 来自哪里呢?很多图形绘制的是数据集的原始数据,比如散点图。另外一些图形则可以绘制那些计算出的新数据,比如条形图。
・条形图、直方图和频率多边形图可以对数据进行分箱,然后绘制出分箱数量和落在每个分箱的数据点的数量。
・平滑曲线会为数据拟合一个模型,然后绘制出模型预测值。
・箱线图可以计算出数据分布的多种摘要统计量,并显示一个特殊形式的箱体。
绘图时用来计算新数据的算法称为 stat(statistical transformation,统计变换)。下图描述了 geom_bar () 函数的统计变换过程。
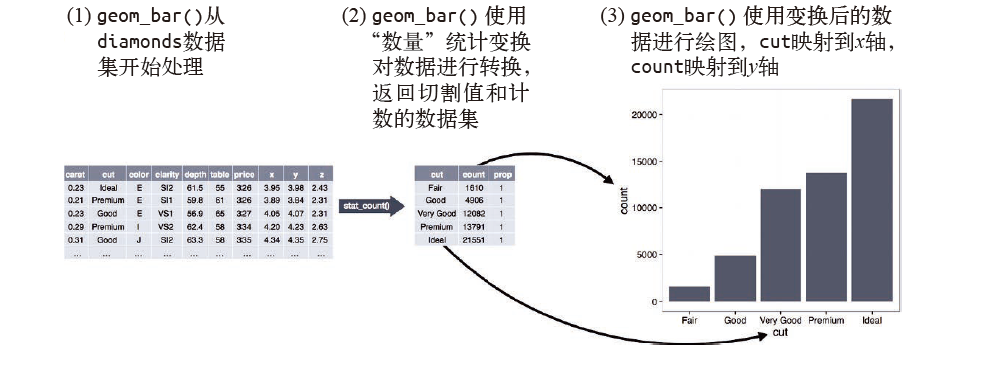
通常来说,几何对象函数和统计变换函数可以互换使用。例如,你可以使用 stat_count () 替换 geom_bar () 来重新生成前面那张图:
ggplot(data = diamonds) + | |
stat_count(mapping = aes(x = cut)) |
你可能想要覆盖从统计变换生成的变量到图形属性的默认映射。例如,你或许想显示一张表示比例(而不是计数)的条形图:
ggplot(data = diamonds) + | |
geom_bar( | |
mapping = aes(x = cut, y = ..prop.., group = 1) | |
) |
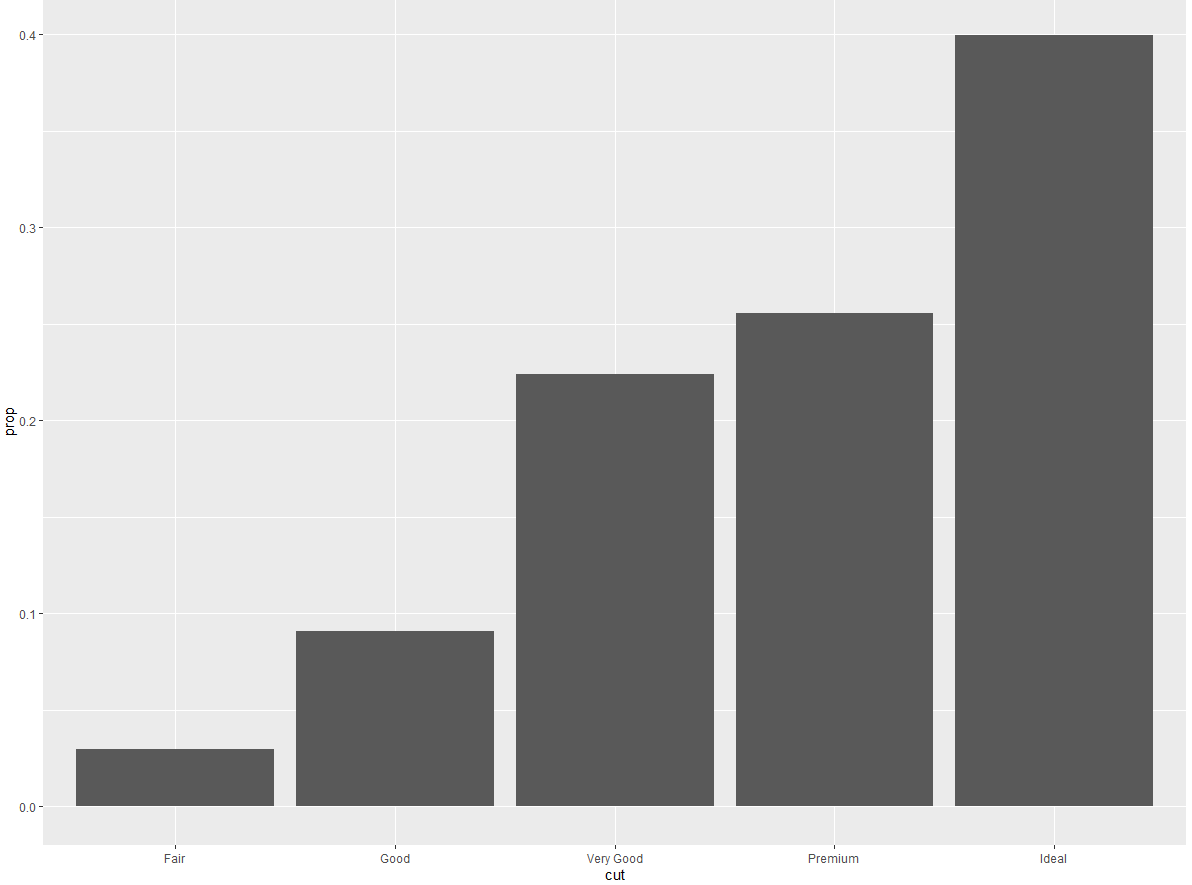
你可能想要在代码中强调统计变换。例如,你可以使用 stat_summary () 函数将人们的注意力吸引到你计算出的那些摘要统计量上。stat_summary () 函数为 x 的每个唯一值计算 y 值的摘要统计:
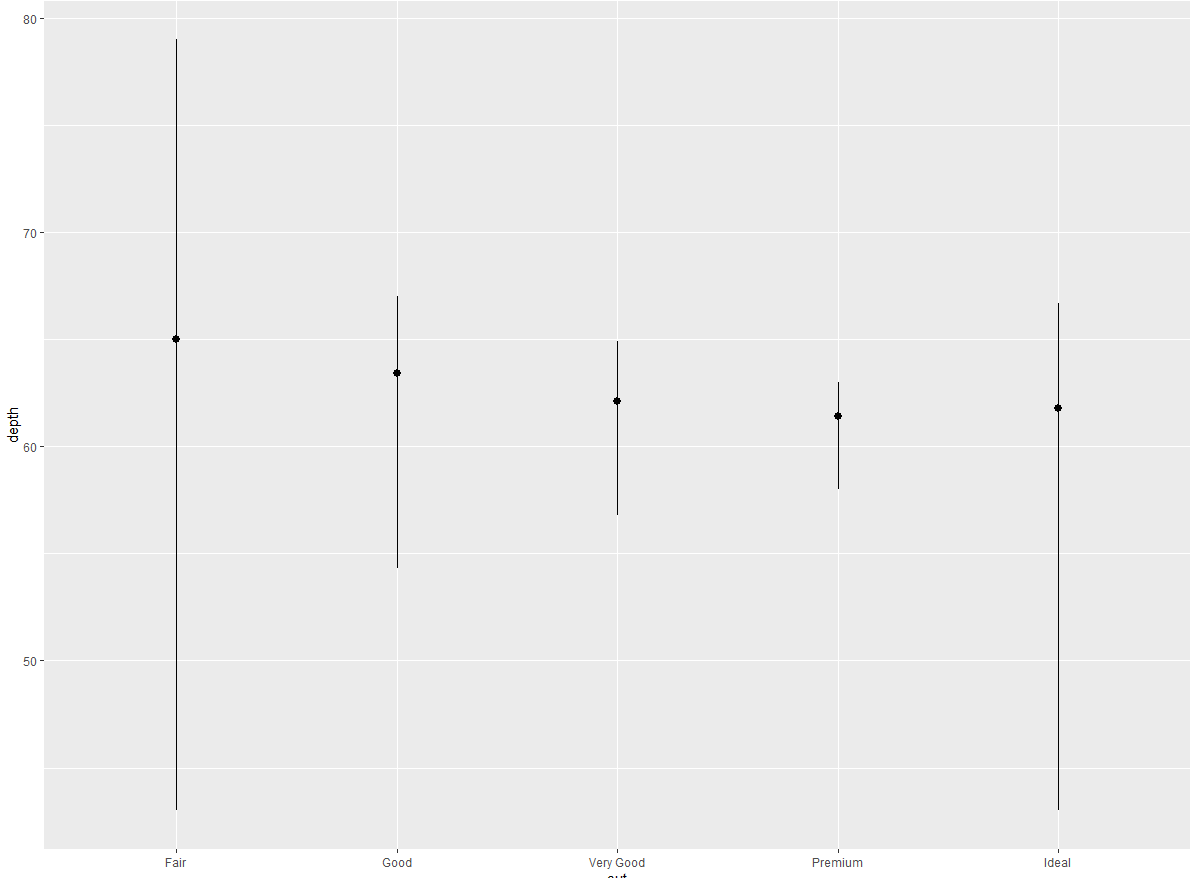
ggplot2 提供了 20 多个统计变换以供你使用。每个统计变换都是一个函数,因此你可以按照通用方式获得帮助,例如?stat_bin。如果想要查看全部的统计变换,可以使用 ggplot2 速查表。
# 练习
(1) stat_summary () 函数的默认几何对象是什么?不使用统计变换函数的话,如何使用几何对象函数重新生成以上的图?
geom_pointrange,
(2) geom_col () 函数的功能是什么?它和 geom_bar () 函数有何不同?
直方图,其中柱状图的高度表示数据中的值,geom_col () 的默认统计变换为 identity (),geom_bar () 默认为 count ()
# 1.8 位置调整
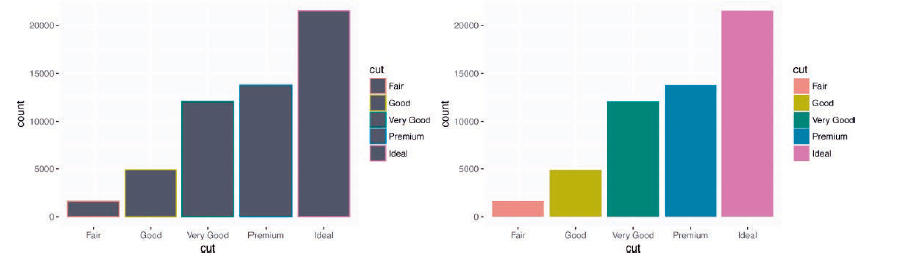
可以使用 color 或者 fill(这个更有用)图形属性来为条形图上色:
ggplot(data = diamonds) + | |
geom_bar(mapping = aes(x = cut, color = cut)) | |
ggplot(data = diamonds) + | |
geom_bar(mapping = aes(x = cut, fill = cut)) |
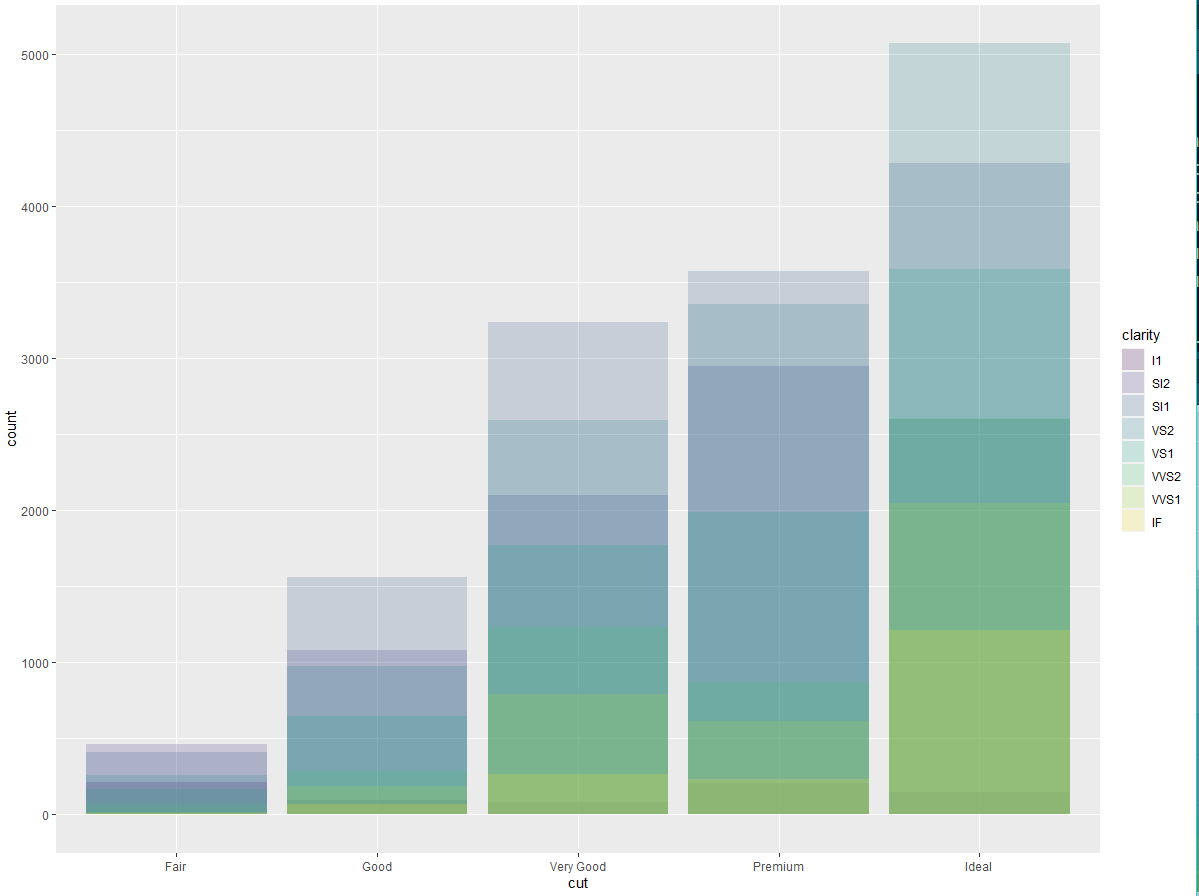
如果将 fill 图形属性映射到另一个变量(如 clarity),那么条形会自动分块堆叠起来。每个彩色矩形表示 cut 和 clarity 的一种组合。
ggplot(data = diamonds) + | |
geom_bar(mapping = aes(x = cut, fill = clarity)) |
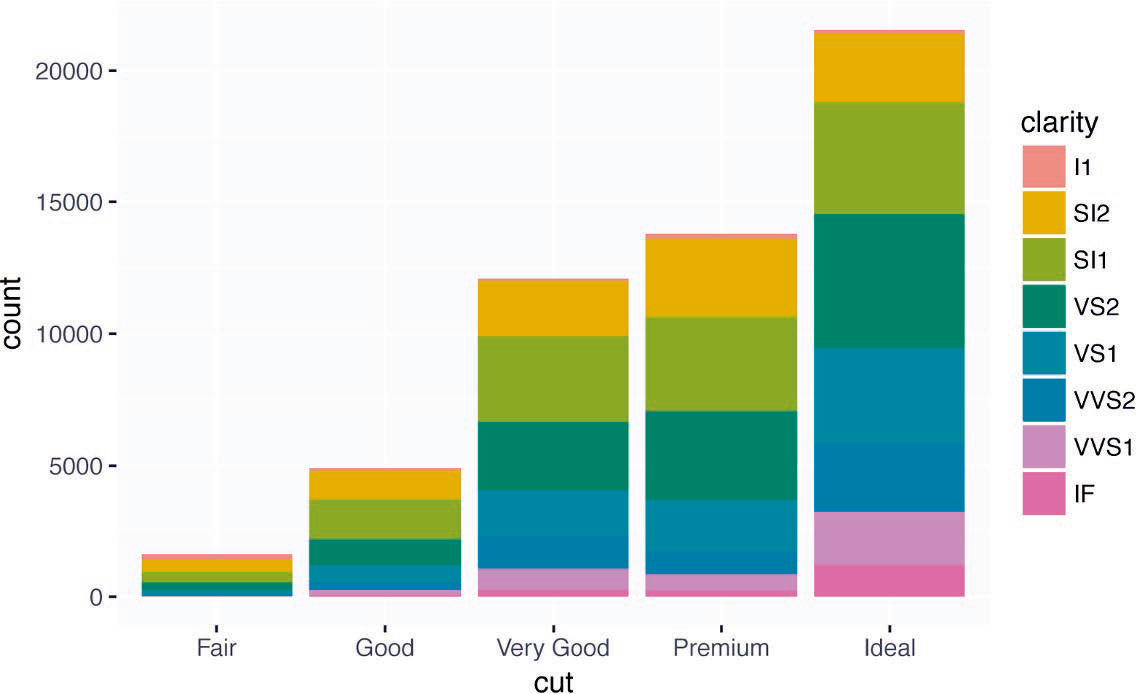
这种堆叠是由 position 参数设定的位置调整功能自动完成的。如果不想生成堆叠式条形图,你还可以使用以下 3 种选项之一:"identity"、"fill" 和 "dodge"。
・position = "identity" 将每个对象直接显示在图中。这种方式不太适合条形图,因为条形会彼此重叠。为了让重叠部分能够显示出来,我们可以设置 alpha 参数为一个较小的数,从而使得条形略微透明;或者设定 fill = NA,让条形完全透明:
ggplot( | |
data = diamonds, | |
mapping = aes(x = cut, fill = clarity) | |
) + | |
geom_bar(alpha = 1/5, position = "identity") | |
ggplot( | |
data = diamonds, | |
mapping = aes(x = cut, color = clarity) | |
) + | |
geom_bar(fill = NA, position = "identity") |
・position = "fill" 的效果与堆叠相似,但每组堆叠条形具有同样的高度,因此这种条形图可以非常轻松地比较各组间的比例:
ggplot(data = diamonds) + | |
geom_bar( | |
mapping = aes(x = cut, fill = clarity), | |
position = "fill" | |
) |
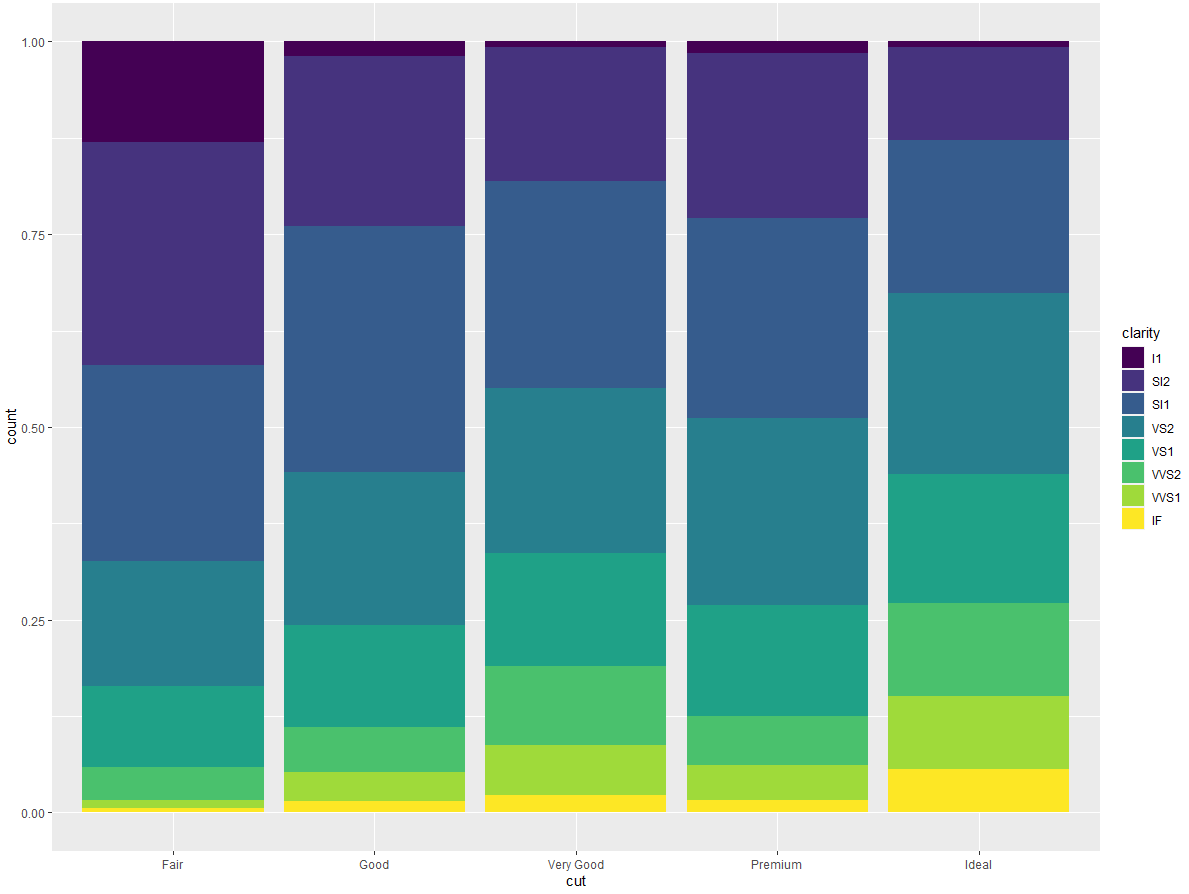
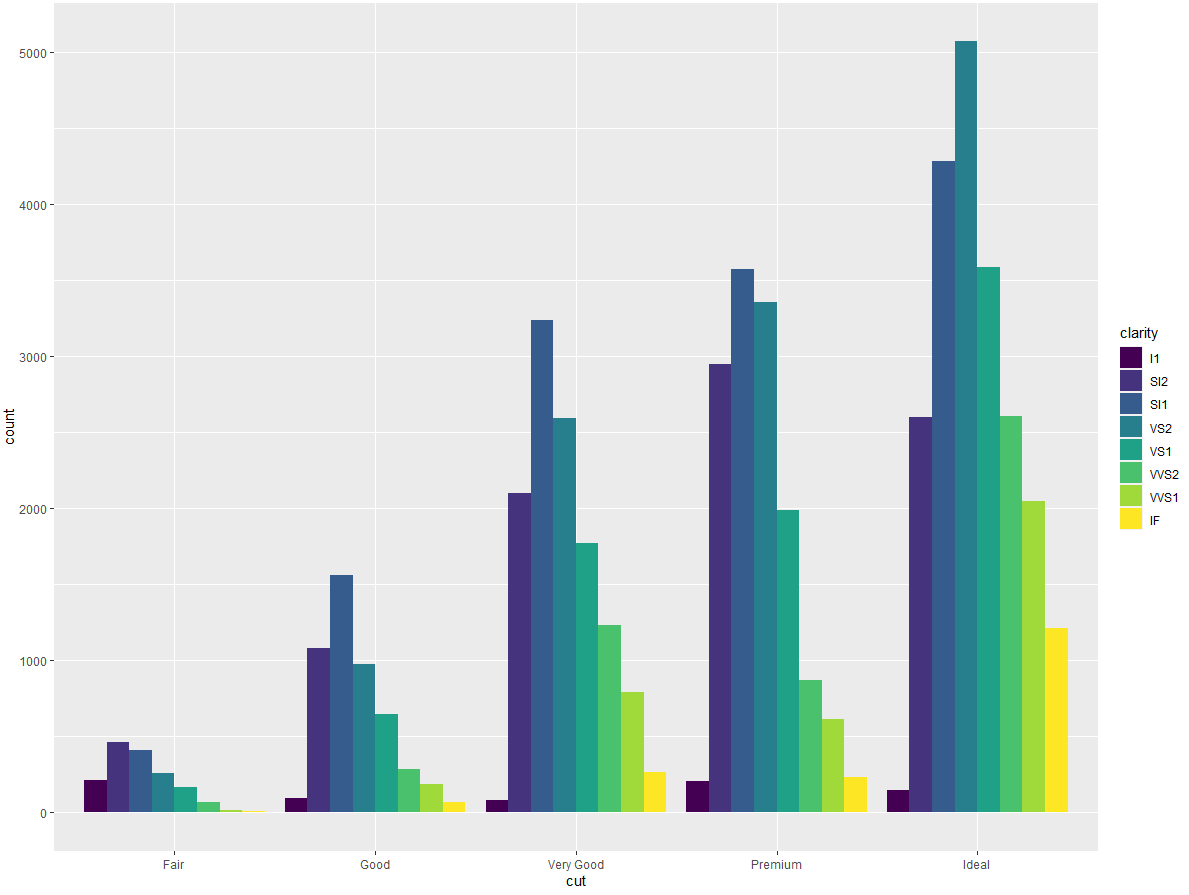
・position = "dodge" 将每组中的条形依次并列放置,这样可以非常轻松地比较每个条形表示的具体数值:
ggplot(data = diamonds) + | |
geom_bar( | |
mapping = aes(x = cut, fill = clarity), | |
position = "dodge" | |
) |
回忆一下我们的第一张散点图。你是否发现,虽然数据集中有 234 个观测值,但散点图中只显示了 126 个点?
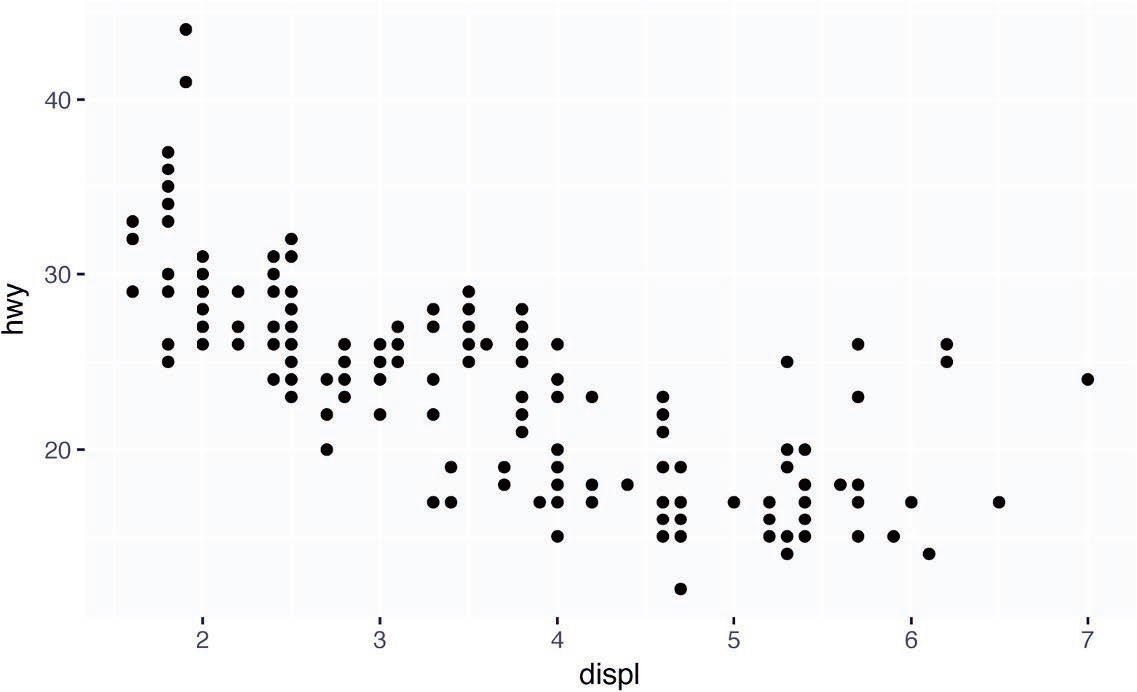
因为 hwy 和 displ 的值都进行了舍入取整,所以这些点显示在一个网格上时,很多点彼此重叠了。这个问题称为过绘制。点的这种排列方式很难看出数据的聚集模式。数据点是均匀地分布在图中,还是存在 hwy 和 displ 的特殊组合,其中包括了 109 个点?
通过将位置调整方式设为 “抖动”,可以避免这种网格化排列。position = "jitter" 为每个数据点添加一个很小的随机扰动,这样就可以将重叠的点分散开来,因为不可能有两个点会收到同样的随机扰动:
添加随机性来改善图形似乎是一种奇怪的方式,然而尽管这种方式会损失图形的精确性,但可以大大提高图形的启发性。因为这种操作的用处非常大,所以 ggplot2 提供了 geom_point (position = "jitter") 的一种快速实现方式:geom_jitter ()。
# 1.9 坐标系
坐标系可能是 ggplot2 中最复杂的部分。默认的坐标系是笛卡儿直角坐标系,可以通过其独立作用的 x 坐标和 y 坐标找到每个数据点。偶尔也会用到一些其他类型的坐标系。
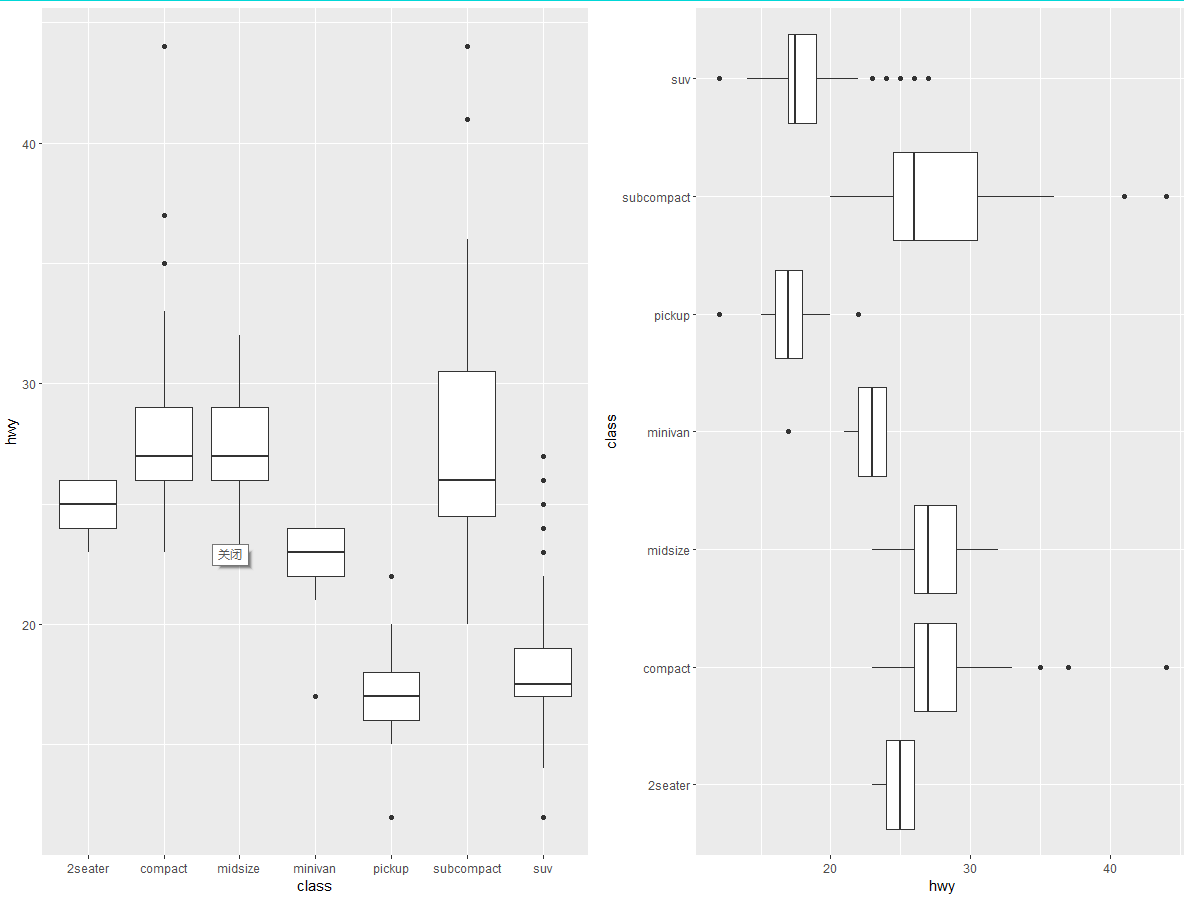
・coord_flip () 函数可以交换 x 轴和 y 轴。当想要绘制水平箱线图时,这非常有用。它也非常适合使用长标签,但要想在 x 轴上不重叠地安排好它们是非常困难的:
ggplot(data = mpg, mapping = aes(x = class, y = hwy)) + | |
geom_boxplot() | |
ggplot(data = mpg, mapping = aes(x = class, y = hwy)) + | |
geom_boxplot() + | |
coord_flip() |
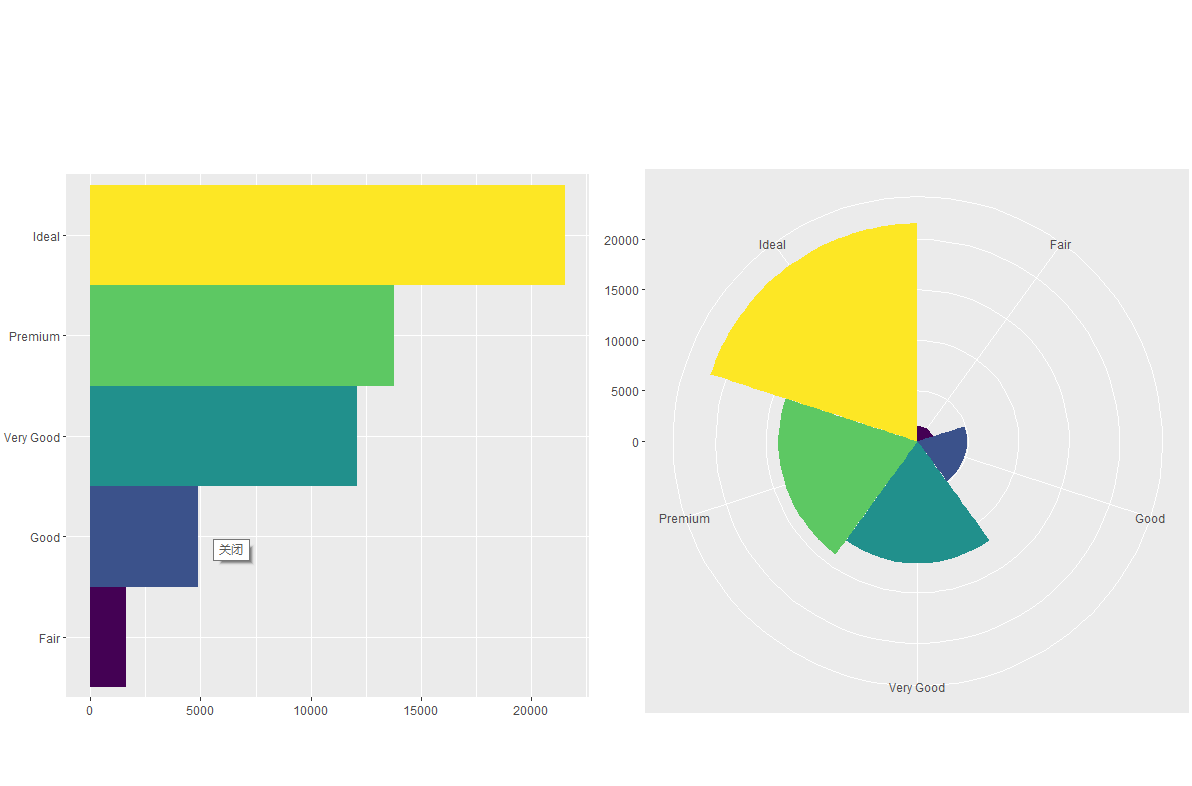
・coord_polar () 函数使用极坐标系。极坐标系可以揭示出条形图和鸡冠花图间的一种有趣联系:
bar <- ggplot(data = diamonds) + | |
geom_bar( | |
mapping = aes(x = cut, fill = cut), | |
show.legend = FALSE, | |
width = 1 | |
) + | |
theme(aspect.ratio = 1) + | |
labs(x = NULL, y = NULL) | |
p1<-bar + coord_flip() | |
p2<-bar + coord_polar() | |
ggarrange(p1, p2) |
# 1.10 图形分层语法
在前面几节中,你学到的绝不仅仅是如何绘制散点图、条形图和箱线图,而是使用 ggplot2 绘制任何类型图形的基础知识。为了说明这一点,我们向前面的代码模板中添加位置调整、统计变换、坐标系和分面:
ggplot(data = <DATA>) + | |
<GEOM_FUNCTION>( | |
mapping = aes(<MAPPINGS>), | |
stat = <STAT>, | |
position = <POSITION> | |
) + | |
<COORDINATE_FUNCTION> + | |
<FACET_FUNCTION> |
为了说明图形语法的工作方式,我们看一下如何从头开始构建一个基本图形:首先需要有一个数据集,然后(通过统计变换)将其转换为想要显示的信息。
接下来,你可以选择一个几何对象来表示转换后的数据中的每个观测值,然后选择几何对象的图形属性来表示数据中的变量,这会将每个变量的值映射为图形属性的水平。

下一步是选择放置几何对象的坐标系。你可以使用对象位置(对象本身的一个图形属性)来显示 x 变量和 y 变量的值。这样就生成了一张完整的图。但你还可以进一步调整几何对象在坐标系中的位置(位置调整),或者将图划分为多个子图(分面)。你还可以通过添加一个或多个附加图层对图进行扩展,其中每个附加图层都使用一个数据集、一个几何对象、一个映射集合、一个统计变换和一个位置调整。